138 lines
5.7 KiB
Markdown
138 lines
5.7 KiB
Markdown
> **免责声明:**
|
||
|
||
>本仓库的所有内容仅供学习和参考之用,禁止用于商业用途。任何人或组织不得将本仓库的内容用于非法用途或侵犯他人合法权益。本仓库所涉及的爬虫技术仅用于学习和研究,不得用于对其他平台进行大规模爬虫或其他非法行为。对于因使用本仓库内容而引起的任何法律责任,本仓库不承担任何责任。使用本仓库的内容即表示您同意本免责声明的所有条款和条件。
|
||
|
||
# 仓库描述
|
||
|
||
**小红书爬虫**,**抖音爬虫** ...。
|
||
目前能稳定抓取小红书的视频、图片、评论、点赞、转发等信息,抖音的视频、图片、评论、点赞等信息。
|
||
|
||
原理:利用[playwright](https://playwright.dev/)搭桥,保留登录成功后的上下文浏览器环境,通过执行JS表达式获取一些加密参数
|
||
通过使用此方式,免去了复现核心加密JS代码,逆向难度大大降低。
|
||
|
||
|
||
## 已实现
|
||
|
||
- [x] 小红书登录(二维码、手机号、cookies)
|
||
- [x] 小红书Sign请求签名
|
||
- [x] 抖音Sign请求签名
|
||
- [x] 代理池实现(手机号+IP)
|
||
- [x] 并发执行爬虫请求
|
||
- [x] 抖音登录(二维码、手机号、cookies)
|
||
- [x] 抖音滑块(模拟滑动实现,准确率不太OK)
|
||
- [x] 支持登录成功后的上下文浏览器环境保留
|
||
- [x] 数据保存到CSV中(默认)
|
||
- [x] 数据保持到数据库中(可选)
|
||
|
||
|
||
## 使用方法
|
||
|
||
1. 安装依赖库
|
||
|
||
```shell
|
||
pip install -r requirements.txt
|
||
```
|
||
|
||
2. 安装playwright浏览器驱动
|
||
|
||
```shell
|
||
playwright install
|
||
```
|
||
|
||
3. 是否保存数据到DB中
|
||
|
||
如果选择开启,则需要配置数据库连接信息,`config/db_config.py` 中的 `IS_SAVED_DATABASED`和`RELATION_DB_URL` 变量。然后执行以下命令初始化数据库信息,生成相关的数据库表结构:
|
||
|
||
```shell
|
||
python db.py
|
||
```
|
||
|
||
4. 运行爬虫程序
|
||
|
||
```shell
|
||
python main.py --platform xhs --lt qrcode
|
||
```
|
||
|
||
5. 打开对应APP扫二维码登录
|
||
|
||
6. 等待爬虫程序执行完毕,数据会保存到 `data/xhs` 目录下
|
||
|
||
|
||
## 项目代码结构
|
||
|
||
```
|
||
MediaCrawler
|
||
├── base
|
||
│ ├── base_crawler.py # 项目的抽象类
|
||
│ └── proxy_account_pool.py # 账号与IP代理池
|
||
├── browser_data # 浏览器数据目录
|
||
├── config
|
||
│ ├── account_config.py # 账号代理池配置
|
||
│ ├── base_config.py # 基础配置
|
||
│ └── db_config.py # 数据库配置
|
||
├── data # 数据保存目录
|
||
├── libs
|
||
│ ├── douyin.js # 抖音Sign函数
|
||
│ └── stealth.min.js # 去除浏览器自动化特征的JS
|
||
├── media_platform
|
||
│ ├── douyin # 抖音crawler实现
|
||
│ │ ├── client.py # httpx 请求封装
|
||
│ │ ├── core.py # 核心实现
|
||
│ │ ├── exception.py # 异常处理
|
||
│ │ ├── field.py # 字段定义
|
||
│ │ └── login.py # 登录实现
|
||
│ └── xiaohongshu # 小红书crawler实现
|
||
│ ├── client.py # API httpx 请求封装
|
||
│ ├── core.py # 核心实现
|
||
│ ├── exception.py # 异常处理
|
||
│ ├── field.py # 字段定义
|
||
│ ├── help.py # 辅助函数
|
||
│ └── login.py # 登录实现
|
||
├── modles
|
||
│ ├── douyin.py # 抖音数据模型
|
||
│ └── xiaohongshu.py # 小红书数据模型
|
||
├── tools
|
||
│ └── utils.py # 工具函数
|
||
├── main.py # 程序入口
|
||
└── recv_sms_notification.py # 短信转发器的HTTP SERVER接口
|
||
```
|
||
## 数据持久化
|
||
|
||
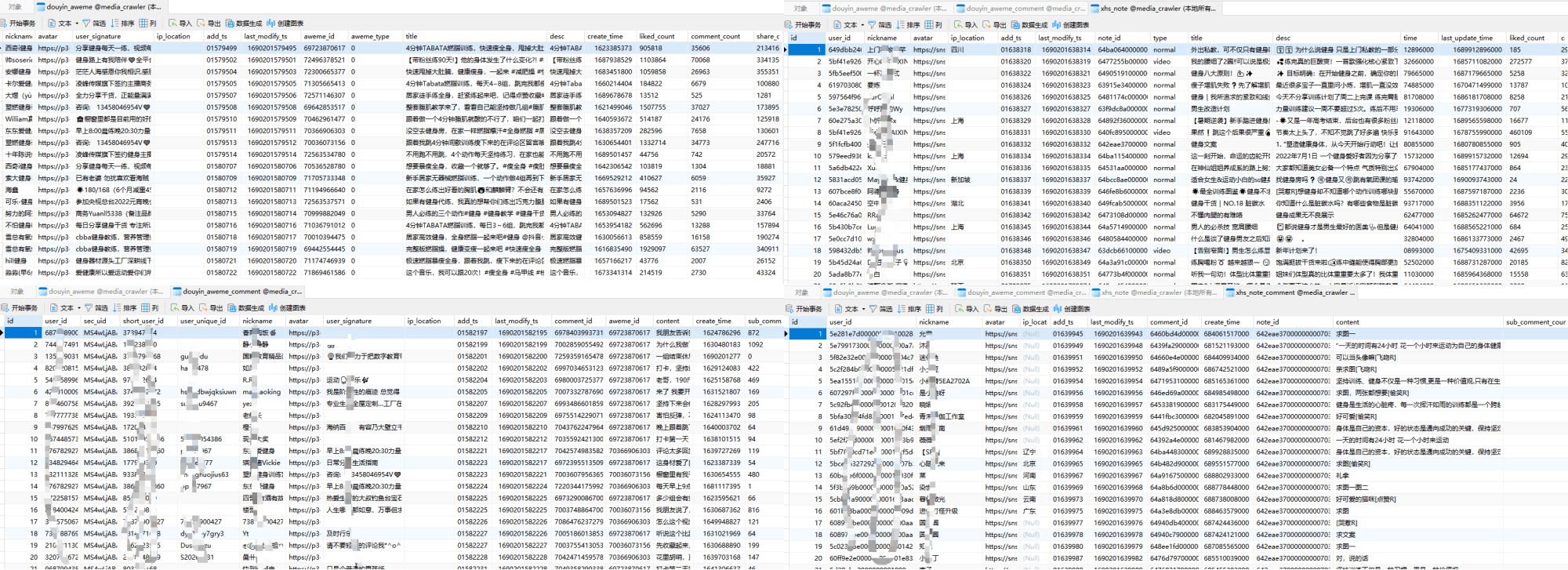
|
||
|
||
## 支持一下
|
||
|
||
- 如果该项目对你有帮助,star一下 ❤️❤️❤️
|
||
|
||
[](https://star-history.com/#NanmiCoder/MediaCrawler&Date)
|
||
|
||
|
||
## 关于手机号+验证码登录的说明
|
||
|
||
当在浏览器模拟人为发起手机号登录请求时,使用短信转发软件将验证码发送至爬虫端回填,完成自动登录
|
||
|
||
准备工作:
|
||
|
||
- 安卓机1台(IOS没去研究,理论上监控短信也是可行的)
|
||
- 安装短信转发软件 [参考仓库](https://github.com/pppscn/SmsForwarder)
|
||
- 转发软件中配置WEBHOOK相关的信息,主要分为 消息模板(请查看本项目中的recv_sms_notification.py)、一个能push短信通知的API地址
|
||
- push的API地址一般是需要绑定一个域名的(当然也可以是内网的IP地址),我用的是内网穿透方式,会有一个免费的域名绑定到内网的web
|
||
server,内网穿透工具 [ngrok](https://ngrok.com/docs/)
|
||
- 安装redis并设置一个密码 [redis安装](https://www.cnblogs.com/hunanzp/p/12304622.html)
|
||
- 执行 `python recv_sms_notification.py` 等待短信转发器发送HTTP通知
|
||
- 执行手机号登录的爬虫程序 `python main.py --platform xhs --lt phone`
|
||
|
||
备注:
|
||
|
||
- 小红书这边一个手机号一天只能发10条短信(悠着点),目前在发验证码时还未触发滑块验证,估计多了之后也会有~
|
||
- 短信转发软件会不会监控自己手机上其他短信内容?(理论上应该不会,因为[短信转发仓库](https://github.com/pppscn/SmsForwarder)
|
||
star还是蛮多的)
|
||
|
||
|
||
## 参考
|
||
|
||
- xhs客户端 [ReaJason的xhs仓库](https://github.com/ReaJason/xhs)
|
||
- 短信转发 [参考仓库](https://github.com/pppscn/SmsForwarder)
|
||
- 内网穿透工具 [ngrok](https://ngrok.com/docs/)
|
||
|