feat: 小红书笔记搜索,评论获取done
docs: update docs Create .gitattributes Update README.md
This commit is contained in:
parent
bca6a27717
commit
e82dcae02f
|
|
@ -0,0 +1,3 @@
|
|||
*.js linguist-language=python
|
||||
*.css linguist-language=python
|
||||
*.html linguist-language=python
|
||||
|
|
@ -158,3 +158,7 @@ cython_debug/
|
|||
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
||||
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
||||
#.idea/
|
||||
|
||||
*.xml
|
||||
*.iml
|
||||
.idea
|
||||
|
|
@ -0,0 +1,37 @@
|
|||
> **!!免责声明:!!**
|
||||
|
||||
> 本仓库的所有内容仅供学习和参考之用,禁止用于商业用途。任何人或组织不得将本仓库的内容用于非法用途或侵犯他人合法权益。本仓库所涉及的爬虫技术仅用于学习和研究,不得用于对其他平台进行大规模爬虫或其他非法行为。对于因使用本仓库内容而引起的任何法律责任,本仓库不承担任何责任。使用本仓库的内容即表示您同意本免责声明的所有条款和条件。
|
||||
|
||||
# 仓库描述
|
||||
这个代码仓库是一个利用[playwright](https://playwright.dev/)的爬虫程序
|
||||
可以准确地爬取小红书、抖音的笔记、评论等信息,大概原理是:利用playwright登录成功后,保留登录成功后的上下文浏览器环境,通过上下文浏览器环境执行JS表达式获取一些加密参数,再使用python的httpx发起异步请求,相当于使用Playwright搭桥,免去了复现核心加密JS代码,逆向难度大大降低。
|
||||
|
||||
|
||||
## 主要功能
|
||||
|
||||
- [x] 爬取小红书笔记、评论
|
||||
- [ ] To do 爬取抖音视频、评论
|
||||
|
||||
## 技术栈
|
||||
|
||||
- playwright
|
||||
- httpx
|
||||
- Web逆向
|
||||
|
||||
## 使用方法
|
||||
|
||||
1. 安装依赖库
|
||||
`pip install -r requirements.txt`
|
||||
2. 安装playwright浏览器驱动
|
||||
`playwright install`
|
||||
3. 运行爬虫程序
|
||||
`python main.py --platform xhs --keywords 健身`
|
||||
4. 打开小红书扫二维码登录
|
||||
|
||||
## 运行截图
|
||||
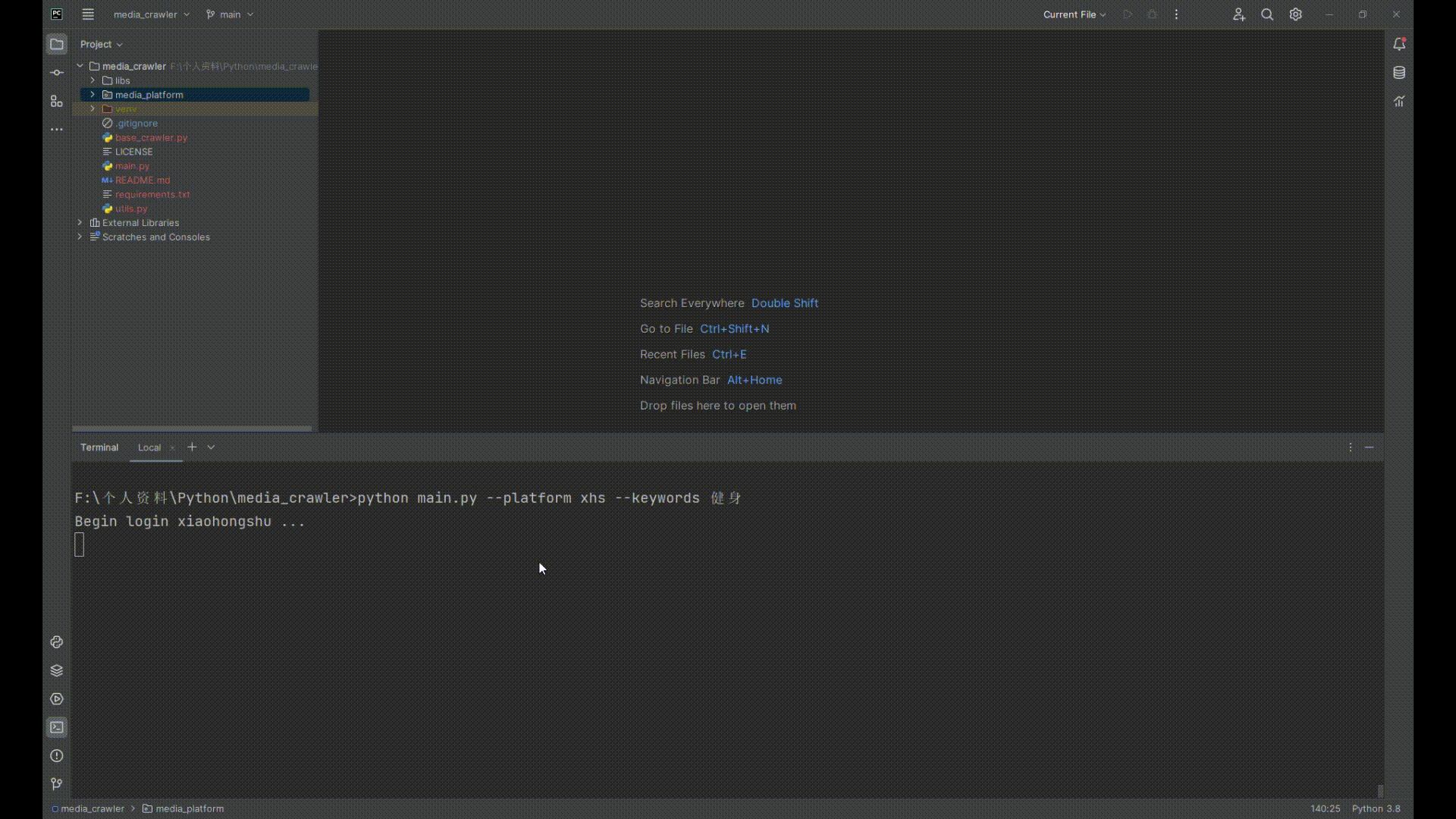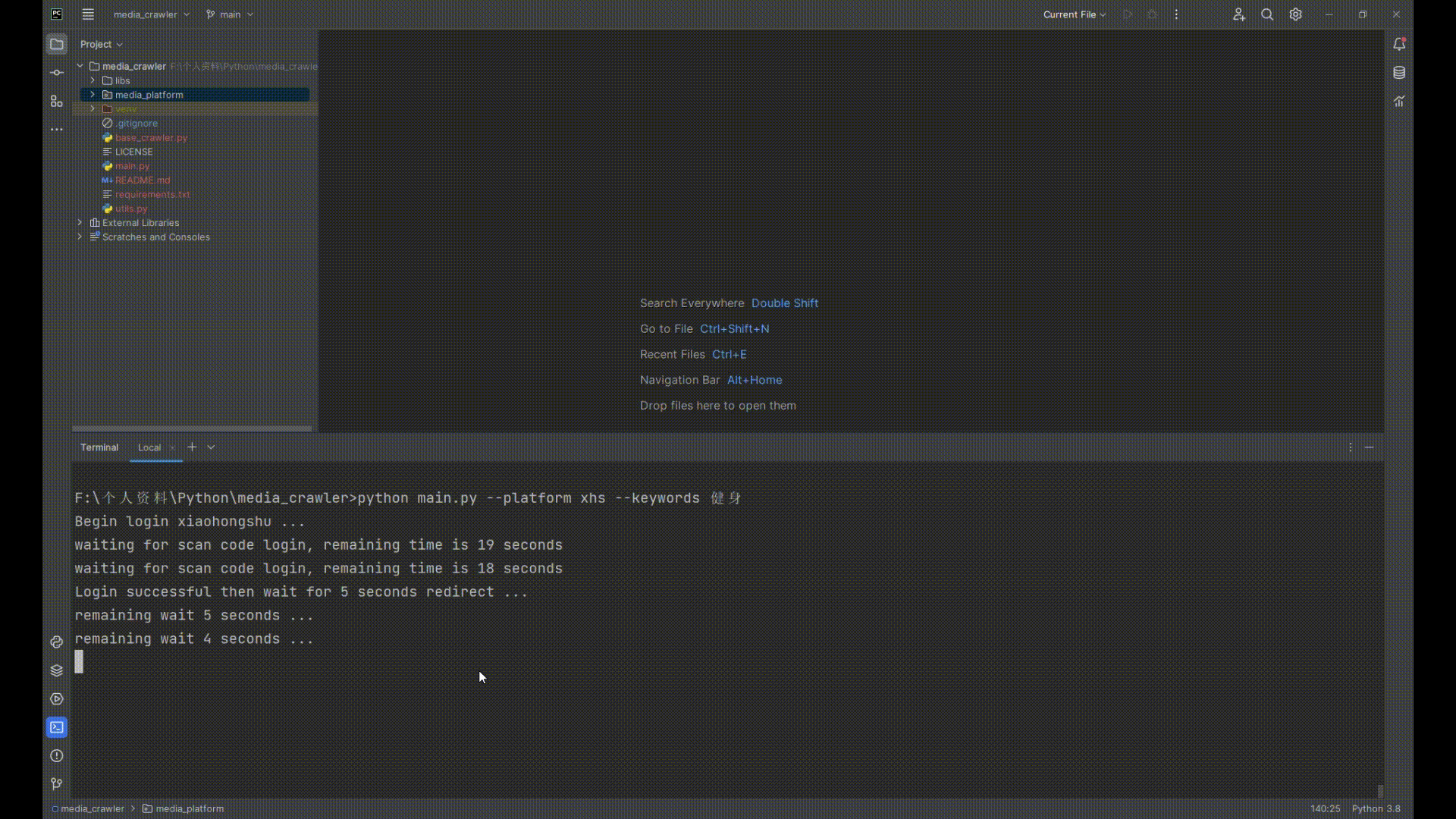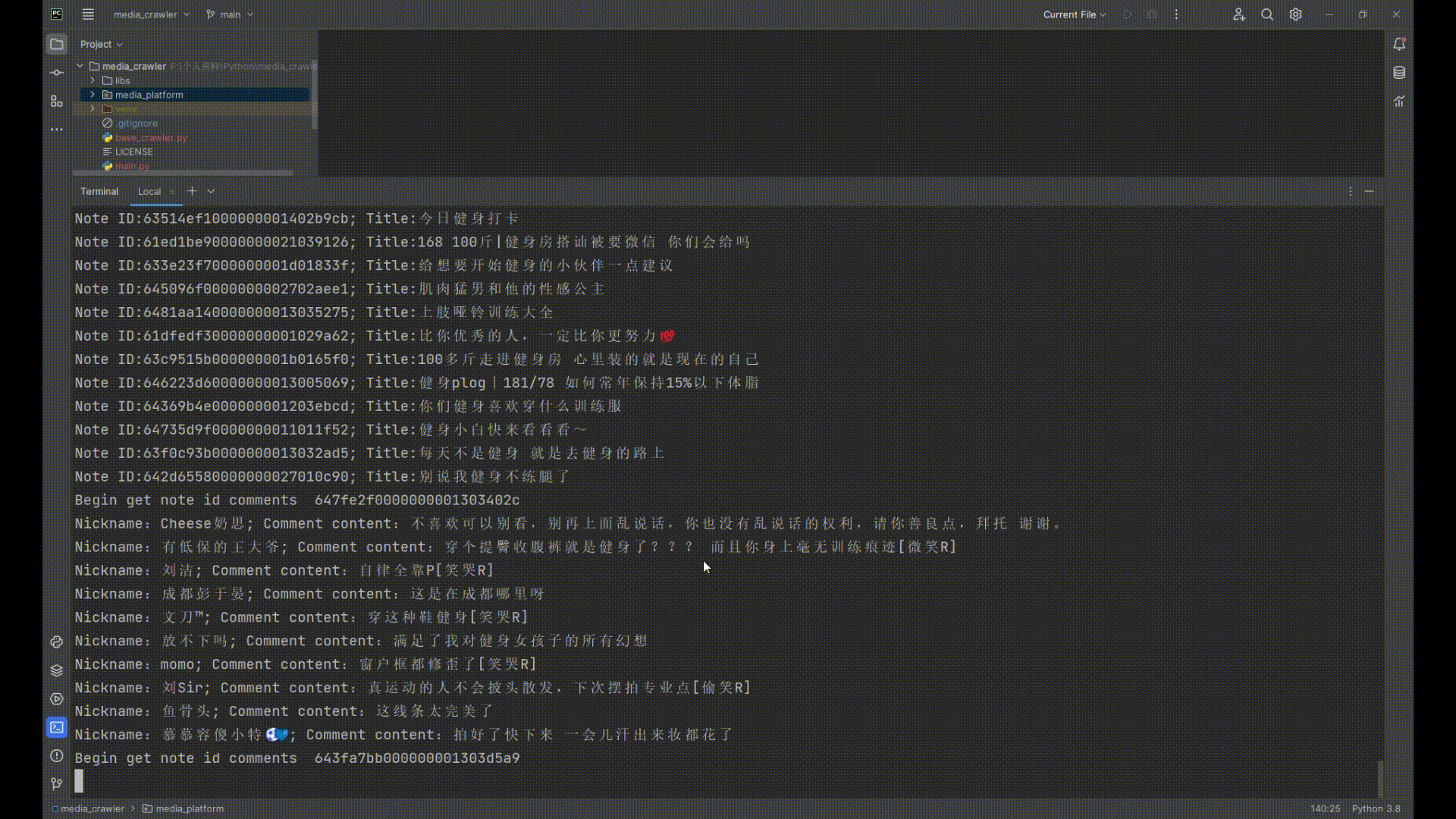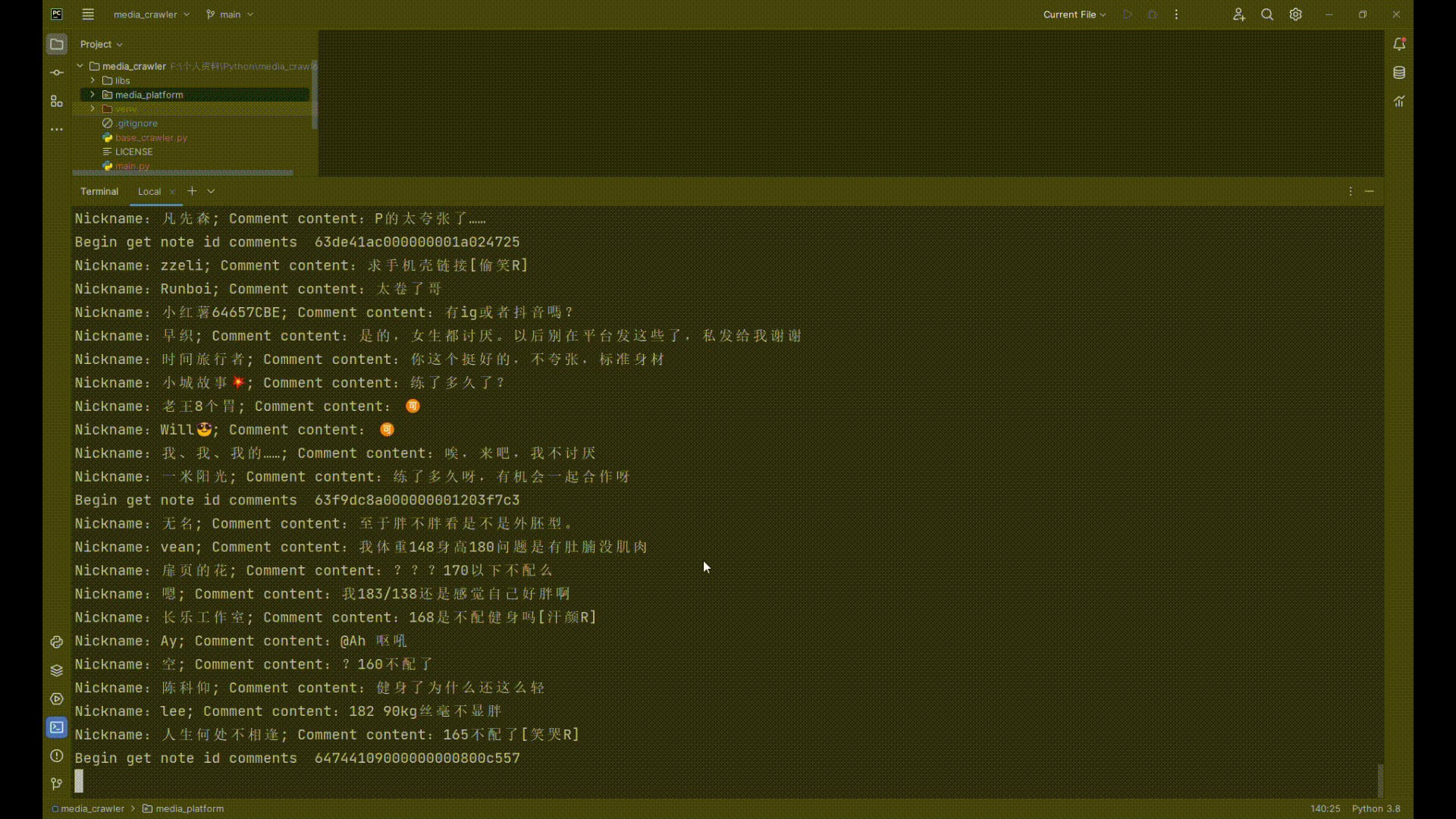
|
||||
|
||||
## 参考
|
||||
本仓库中小红书代码部分来自[ReaJason的xhs仓库](https://github.com/ReaJason/xhs),感谢ReaJason
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,23 @@
|
|||
from abc import ABC, abstractmethod
|
||||
|
||||
|
||||
class Crawler(ABC):
|
||||
@abstractmethod
|
||||
def init_config(self, **kwargs):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
async def start(self):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
async def login(self):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
async def search_posts(self):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
async def get_comments(self, item_id: int):
|
||||
pass
|
||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 2.9 MiB |
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
|
|
@ -0,0 +1,37 @@
|
|||
import sys
|
||||
import asyncio
|
||||
import argparse
|
||||
|
||||
from media_platform.douyin import DouYinCrawler
|
||||
from media_platform.xhs import XiaoHongShuCrawler
|
||||
|
||||
|
||||
class CrawlerFactory:
|
||||
@staticmethod
|
||||
def create_crawler(platform: str):
|
||||
if platform == "xhs":
|
||||
return XiaoHongShuCrawler()
|
||||
elif platform == "dy":
|
||||
return DouYinCrawler()
|
||||
else:
|
||||
raise ValueError("Invalid Media Platform Currently only supported xhs or douyin ...")
|
||||
|
||||
|
||||
async def main():
|
||||
# define command line params ...
|
||||
parser = argparse.ArgumentParser(description='Media crawler program.')
|
||||
parser.add_argument('--platform', type=str, help='Media platform select (xhs|dy)...', default="xhs")
|
||||
parser.add_argument('--keywords', type=str, help='Search note/page keywords...', default="健身")
|
||||
args = parser.parse_args()
|
||||
crawler = CrawlerFactory().create_crawler(platform=args.platform)
|
||||
crawler.init_config(
|
||||
keywords=args.keywords,
|
||||
)
|
||||
await crawler.start()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
try:
|
||||
asyncio.run(main())
|
||||
except KeyboardInterrupt:
|
||||
sys.exit()
|
||||
|
|
@ -0,0 +1 @@
|
|||
from .core import DouYinCrawler
|
||||
|
|
@ -0,0 +1,42 @@
|
|||
from typing import Optional, Dict
|
||||
|
||||
import httpx
|
||||
from playwright.async_api import Page
|
||||
|
||||
|
||||
class DOUYINClient:
|
||||
def __init__(
|
||||
self,
|
||||
timeout=10,
|
||||
proxies=None,
|
||||
headers: Optional[Dict] = None,
|
||||
playwright_page: Page = None,
|
||||
cookie_dict: Dict = None
|
||||
):
|
||||
self.proxies = proxies
|
||||
self.timeout = timeout
|
||||
self.headers = headers
|
||||
self._host = "https://www.douyin.com"
|
||||
self.playwright_page = playwright_page
|
||||
self.cookie_dict = cookie_dict
|
||||
|
||||
async def _pre_params(self, url: str, data=None):
|
||||
pass
|
||||
|
||||
async def request(self, method, url, **kwargs):
|
||||
async with httpx.AsyncClient(proxies=self.proxies) as client:
|
||||
response = await client.request(
|
||||
method, url, timeout=self.timeout,
|
||||
**kwargs
|
||||
)
|
||||
data = response.json()
|
||||
if data["success"]:
|
||||
return data.get("data", data.get("success"))
|
||||
else:
|
||||
pass
|
||||
|
||||
async def get(self, uri: str, params=None):
|
||||
pass
|
||||
|
||||
async def post(self, uri: str, data: dict):
|
||||
pass
|
||||
|
|
@ -0,0 +1,61 @@
|
|||
import sys
|
||||
import asyncio
|
||||
from typing import Optional, List, Dict
|
||||
|
||||
from playwright.async_api import async_playwright
|
||||
from playwright.async_api import Page
|
||||
from playwright.async_api import Cookie
|
||||
from playwright.async_api import BrowserContext
|
||||
|
||||
import utils
|
||||
from .client import DOUYINClient
|
||||
from base_crawler import Crawler
|
||||
|
||||
|
||||
class DouYinCrawler(Crawler):
|
||||
def __init__(self):
|
||||
self.keywords: Optional[str] = None
|
||||
self.scan_qrcode_time: Optional[int] = None
|
||||
self.cookies: Optional[List[Cookie]] = None
|
||||
self.browser_context: Optional[BrowserContext] = None
|
||||
self.context_page: Optional[Page] = None
|
||||
self.proxy: Optional[Dict] = None
|
||||
self.user_agent = utils.get_user_agent()
|
||||
self.dy_client: Optional[DOUYINClient] = None
|
||||
|
||||
def init_config(self, **kwargs):
|
||||
self.keywords = kwargs.get("keywords")
|
||||
self.scan_qrcode_time = kwargs.get("scan_qrcode_time")
|
||||
|
||||
async def start(self):
|
||||
async with async_playwright() as playwright:
|
||||
chromium = playwright.chromium
|
||||
browser = await chromium.launch(headless=False)
|
||||
self.browser_context = await browser.new_context(
|
||||
viewport={"width": 1920, "height": 1080},
|
||||
user_agent=self.user_agent,
|
||||
proxy=self.proxy
|
||||
)
|
||||
# execute JS to bypass anti automation/crawler detection
|
||||
await self.browser_context.add_init_script(path="libs/stealth.min.js")
|
||||
self.context_page = await self.browser_context.new_page()
|
||||
await self.context_page.goto("https://www.douyin.com")
|
||||
|
||||
# scan qrcode login
|
||||
await self.login()
|
||||
await self.update_cookies()
|
||||
|
||||
# block main crawler coroutine
|
||||
await asyncio.Event().wait()
|
||||
|
||||
async def update_cookies(self):
|
||||
self.cookies = await self.browser_context.cookies()
|
||||
|
||||
async def login(self):
|
||||
pass
|
||||
|
||||
def search_posts(self):
|
||||
pass
|
||||
|
||||
def get_comments(self, item_id: str):
|
||||
pass
|
||||
|
|
@ -0,0 +1,2 @@
|
|||
from .core import XiaoHongShuCrawler
|
||||
from .field import *
|
||||
|
|
@ -0,0 +1,199 @@
|
|||
import json
|
||||
import asyncio
|
||||
from typing import Optional, Dict
|
||||
|
||||
import httpx
|
||||
from playwright.async_api import Page
|
||||
|
||||
from .help import sign, get_search_id
|
||||
from .field import SearchSortType, SearchNoteType
|
||||
from .exception import DataFetchError, IPBlockError
|
||||
|
||||
|
||||
class XHSClient:
|
||||
def __init__(
|
||||
self,
|
||||
timeout=10,
|
||||
proxies=None,
|
||||
headers: Optional[Dict] = None,
|
||||
playwright_page: Page = None,
|
||||
cookie_dict: Dict = None
|
||||
):
|
||||
self.proxies = proxies
|
||||
self.timeout = timeout
|
||||
self.headers = headers
|
||||
self._host = "https://edith.xiaohongshu.com"
|
||||
self.IP_ERROR_STR = "网络连接异常,请检查网络设置或重启试试"
|
||||
self.IP_ERROR_CODE = 300012
|
||||
self.NOTE_ABNORMAL_STR = "笔记状态异常,请稍后查看"
|
||||
self.NOTE_ABNORMAL_CODE = -510001
|
||||
self.playwright_page = playwright_page
|
||||
self.cookie_dict = cookie_dict
|
||||
|
||||
async def _pre_headers(self, url: str, data=None):
|
||||
encrypt_params = await self.playwright_page.evaluate("([url, data]) => window._webmsxyw(url,data)", [url, data])
|
||||
local_storage = await self.playwright_page.evaluate("() => window.localStorage")
|
||||
signs = sign(
|
||||
a1=self.cookie_dict.get("a1", ""),
|
||||
b1=local_storage.get("b1", ""),
|
||||
x_s=encrypt_params.get("X-s", ""),
|
||||
x_t=str(encrypt_params.get("X-t", ""))
|
||||
)
|
||||
|
||||
headers = {
|
||||
"X-S": signs["x-s"],
|
||||
"X-T": signs["x-t"],
|
||||
"x-S-Common": signs["x-s-common"],
|
||||
"X-B3-Traceid": signs["x-b3-traceid"]
|
||||
}
|
||||
self.headers.update(headers)
|
||||
return self.headers
|
||||
|
||||
async def request(self, method, url, **kwargs):
|
||||
async with httpx.AsyncClient(proxies=self.proxies) as client:
|
||||
response = await client.request(
|
||||
method, url, timeout=self.timeout,
|
||||
**kwargs
|
||||
)
|
||||
data = response.json()
|
||||
if data["success"]:
|
||||
return data.get("data", data.get("success"))
|
||||
elif data["code"] == self.IP_ERROR_CODE:
|
||||
raise IPBlockError(self.IP_ERROR_STR)
|
||||
else:
|
||||
raise DataFetchError(data.get("msg", None))
|
||||
|
||||
async def get(self, uri: str, params=None):
|
||||
final_uri = uri
|
||||
if isinstance(params, dict):
|
||||
final_uri = (f"{uri}?"
|
||||
f"{'&'.join([f'{k}={v}' for k, v in params.items()])}")
|
||||
headers = await self._pre_headers(final_uri)
|
||||
return await self.request(method="GET", url=f"{self._host}{final_uri}", headers=headers)
|
||||
|
||||
async def post(self, uri: str, data: dict):
|
||||
headers = await self._pre_headers(uri, data)
|
||||
json_str = json.dumps(data, separators=(',', ':'), ensure_ascii=False)
|
||||
return await self.request(method="POST", url=f"{self._host}{uri}",
|
||||
data=json_str, headers=headers)
|
||||
|
||||
async def get_note_by_keyword(
|
||||
self, keyword: str,
|
||||
page: int = 1, page_size: int = 20,
|
||||
sort: SearchSortType = SearchSortType.GENERAL,
|
||||
note_type: SearchNoteType = SearchNoteType.ALL
|
||||
):
|
||||
"""search note by keyword
|
||||
|
||||
:param keyword: what notes you want to search
|
||||
:type keyword: str
|
||||
:param page: page number, defaults to 1
|
||||
:type page: int, optional
|
||||
:param page_size: page size, defaults to 20
|
||||
:type page_size: int, optional
|
||||
:param sort: sort ordering, defaults to SearchSortType.GENERAL
|
||||
:type sort: SearchSortType, optional
|
||||
:param note_type: note type, defaults to SearchNoteType.ALL
|
||||
:type note_type: SearchNoteType, optional
|
||||
:return: {has_more: true, items: []}
|
||||
:rtype: dict
|
||||
"""
|
||||
uri = "/api/sns/web/v1/search/notes"
|
||||
data = {
|
||||
"keyword": keyword,
|
||||
"page": page,
|
||||
"page_size": page_size,
|
||||
"search_id": get_search_id(),
|
||||
"sort": sort.value,
|
||||
"note_type": note_type.value
|
||||
}
|
||||
return await self.post(uri, data)
|
||||
|
||||
async def get_note_by_id(self, note_id: str):
|
||||
"""
|
||||
:param note_id: note_id you want to fetch
|
||||
:type note_id: str
|
||||
:return: {"time":1679019883000,"user":{"nickname":"nickname","avatar":"avatar","user_id":"user_id"},"image_list":[{"url":"https://sns-img-qc.xhscdn.com/c8e505ca-4e5f-44be-fe1c-ca0205a38bad","trace_id":"1000g00826s57r6cfu0005ossb1e9gk8c65d0c80","file_id":"c8e505ca-4e5f-44be-fe1c-ca0205a38bad","height":1920,"width":1440}],"tag_list":[{"id":"5be78cdfdb601f000100d0bc","name":"jk","type":"topic"}],"desc":"裙裙","interact_info":{"followed":false,"liked":false,"liked_count":"1732","collected":false,"collected_count":"453","comment_count":"30","share_count":"41"},"at_user_list":[],"last_update_time":1679019884000,"note_id":"6413cf6b00000000270115b5","type":"normal","title":"title"}
|
||||
:rtype: dict
|
||||
"""
|
||||
data = {"source_note_id": note_id}
|
||||
uri = "/api/sns/web/v1/feed"
|
||||
res = await self.post(uri, data)
|
||||
return res["items"][0]["note_card"]
|
||||
|
||||
async def get_note_comments(self, note_id: str, cursor: str = ""):
|
||||
"""get note comments
|
||||
|
||||
:param note_id: note id you want to fetch
|
||||
:type note_id: str
|
||||
:param cursor: last you get cursor, defaults to ""
|
||||
:type cursor: str, optional
|
||||
:return: {"has_more": true,"cursor": "6422442d000000000700dcdb",comments: [],"user_id": "63273a77000000002303cc9b","time": 1681566542930}
|
||||
:rtype: dict
|
||||
"""
|
||||
uri = "/api/sns/web/v2/comment/page"
|
||||
params = {
|
||||
"note_id": note_id,
|
||||
"cursor": cursor
|
||||
}
|
||||
return await self.get(uri, params)
|
||||
|
||||
async def get_note_sub_comments(self, note_id: str,
|
||||
root_comment_id: str,
|
||||
num: int = 30, cursor: str = ""):
|
||||
"""get note sub comments
|
||||
|
||||
:param note_id: note id you want to fetch
|
||||
:type note_id: str
|
||||
:param root_comment_id: parent comment id
|
||||
:type root_comment_id: str
|
||||
:param num: recommend 30, if num greater 30, it only return 30 comments
|
||||
:type num: int
|
||||
:param cursor: last you get cursor, defaults to ""
|
||||
:type cursor: str optional
|
||||
:return: {"has_more": true,"cursor": "6422442d000000000700dcdb",comments: [],"user_id": "63273a77000000002303cc9b","time": 1681566542930}
|
||||
:rtype: dict
|
||||
"""
|
||||
uri = "/api/sns/web/v2/comment/sub/page"
|
||||
params = {
|
||||
"note_id": note_id,
|
||||
"root_comment_id": root_comment_id,
|
||||
"num": num,
|
||||
"cursor": cursor,
|
||||
}
|
||||
return await self.get(uri, params)
|
||||
|
||||
async def get_note_all_comments(self, note_id: str, crawl_interval: int = 1):
|
||||
"""get note all comments include sub comments
|
||||
|
||||
:param crawl_interval:
|
||||
:param note_id: note id you want to fetch
|
||||
:type note_id: str
|
||||
"""
|
||||
result = []
|
||||
comments_has_more = True
|
||||
comments_cursor = ""
|
||||
while comments_has_more:
|
||||
comments_res = await self.get_note_comments(note_id, comments_cursor)
|
||||
comments_has_more = comments_res.get("has_more", False)
|
||||
comments_cursor = comments_res.get("cursor", "")
|
||||
comments = comments_res["comments"]
|
||||
for comment in comments:
|
||||
result.append(comment)
|
||||
cur_sub_comment_count = int(comment["sub_comment_count"])
|
||||
cur_sub_comments = comment["sub_comments"]
|
||||
result.extend(cur_sub_comments)
|
||||
sub_comments_has_more = comment["sub_comment_has_more"] and len(
|
||||
cur_sub_comments) < cur_sub_comment_count
|
||||
sub_comment_cursor = comment["sub_comment_cursor"]
|
||||
while sub_comments_has_more:
|
||||
page_num = 30
|
||||
sub_comments_res = await self.get_note_sub_comments(note_id, comment["id"], num=page_num,
|
||||
cursor=sub_comment_cursor)
|
||||
sub_comments = sub_comments_res["comments"]
|
||||
sub_comments_has_more = sub_comments_res["has_more"] and len(sub_comments) == page_num
|
||||
sub_comment_cursor = sub_comments_res["cursor"]
|
||||
result.extend(sub_comments)
|
||||
await asyncio.sleep(crawl_interval)
|
||||
await asyncio.sleep(crawl_interval)
|
||||
return result
|
||||
|
|
@ -0,0 +1,153 @@
|
|||
import sys
|
||||
import asyncio
|
||||
from typing import Optional, List, Dict
|
||||
|
||||
from playwright.async_api import Page
|
||||
from playwright.async_api import Cookie
|
||||
from playwright.async_api import BrowserContext
|
||||
from playwright.async_api import async_playwright
|
||||
|
||||
import utils
|
||||
from .client import XHSClient
|
||||
from base_crawler import Crawler
|
||||
|
||||
|
||||
class XiaoHongShuCrawler(Crawler):
|
||||
def __init__(self):
|
||||
self.keywords = None
|
||||
self.scan_qrcode_time = None
|
||||
self.cookies: Optional[List[Cookie]] = None
|
||||
self.browser_context: Optional[BrowserContext] = None
|
||||
self.context_page: Optional[Page] = None
|
||||
self.proxy: Optional[Dict] = None
|
||||
self.user_agent = utils.get_user_agent()
|
||||
self.xhs_client: Optional[XHSClient] = None
|
||||
self.login_url = "https://www.xiaohongshu.com"
|
||||
self.scan_qrcode_time = 20 # second
|
||||
|
||||
def init_config(self, **kwargs):
|
||||
self.keywords = kwargs.get("keywords")
|
||||
|
||||
async def update_cookies(self):
|
||||
self.cookies = await self.browser_context.cookies()
|
||||
|
||||
async def start(self):
|
||||
async with async_playwright() as playwright:
|
||||
# launch browser and create single browser context
|
||||
chromium = playwright.chromium
|
||||
browser = await chromium.launch(headless=True)
|
||||
self.browser_context = await browser.new_context(
|
||||
viewport={"width": 1920, "height": 1080},
|
||||
user_agent=self.user_agent,
|
||||
proxy=self.proxy
|
||||
)
|
||||
|
||||
# execute JS to bypass anti automation/crawler detection
|
||||
await self.browser_context.add_init_script(path="libs/stealth.min.js")
|
||||
self.context_page = await self.browser_context.new_page()
|
||||
await self.context_page.goto(self.login_url)
|
||||
|
||||
# scan qrcode login
|
||||
await self.login()
|
||||
await self.update_cookies()
|
||||
|
||||
# init request client
|
||||
cookie_str, cookie_dict = utils.convert_cookies(self.cookies)
|
||||
self.xhs_client = XHSClient(
|
||||
proxies=self.proxy,
|
||||
headers={
|
||||
"User-Agent": self.user_agent,
|
||||
"Cookie": cookie_str,
|
||||
"Origin": "https://www.xiaohongshu.com",
|
||||
"Referer": "https://www.xiaohongshu.com",
|
||||
"Content-Type": "application/json;charset=UTF-8"
|
||||
},
|
||||
playwright_page=self.context_page,
|
||||
cookie_dict=cookie_dict,
|
||||
)
|
||||
|
||||
# Search for notes and retrieve their comment information.
|
||||
note_res = await self.search_posts()
|
||||
for post_item in note_res.get("items"):
|
||||
note_id = post_item.get("id")
|
||||
await self.get_comments(note_id=note_id)
|
||||
await asyncio.sleep(1)
|
||||
|
||||
# block main crawler coroutine
|
||||
await asyncio.Event().wait()
|
||||
|
||||
async def login(self):
|
||||
"""login xiaohongshu website and keep webdriver login state"""
|
||||
print("Begin login xiaohongshu ...")
|
||||
|
||||
# find login qrcode
|
||||
base64_qrcode_img = await utils.find_login_qrcode(
|
||||
self.context_page,
|
||||
selector="div.login-container > div.left > div.qrcode > img"
|
||||
)
|
||||
current_cookie = await self.browser_context.cookies()
|
||||
_, cookie_dict = utils.convert_cookies(current_cookie)
|
||||
no_logged_in_session = cookie_dict.get("web_session")
|
||||
if not base64_qrcode_img:
|
||||
|
||||
if await self.check_login_state(no_logged_in_session):
|
||||
return
|
||||
# todo ...if this website does not automatically popup login dialog box, we will manual click login button
|
||||
print("login failed , have not found qrcode please check ....")
|
||||
sys.exit()
|
||||
|
||||
# show login qrcode
|
||||
utils.show_qrcode(base64_qrcode_img)
|
||||
|
||||
while self.scan_qrcode_time > 0:
|
||||
await asyncio.sleep(1)
|
||||
self.scan_qrcode_time -= 1
|
||||
print(f"waiting for scan code login, remaining time is {self.scan_qrcode_time} seconds")
|
||||
# get login state from browser
|
||||
if await self.check_login_state(no_logged_in_session):
|
||||
# If the QR code login is successful, you need to wait for a moment.
|
||||
# Because there will be a second redirection after successful login
|
||||
# executing JS during this period may be performed in a Page that has already been destroyed.
|
||||
wait_for_seconds = 5
|
||||
print(f"Login successful then wait for {wait_for_seconds} seconds redirect ...")
|
||||
while wait_for_seconds > 0:
|
||||
await asyncio.sleep(1)
|
||||
print(f"remaining wait {wait_for_seconds} seconds ...")
|
||||
wait_for_seconds -= 1
|
||||
break
|
||||
else:
|
||||
sys.exit()
|
||||
|
||||
async def check_login_state(self, no_logged_in_session: str) -> bool:
|
||||
"""Check if the current login status is successful and return True otherwise return False"""
|
||||
current_cookie = await self.browser_context.cookies()
|
||||
_, cookie_dict = utils.convert_cookies(current_cookie)
|
||||
current_web_session = cookie_dict.get("web_session")
|
||||
if current_web_session != no_logged_in_session:
|
||||
return True
|
||||
return False
|
||||
|
||||
async def search_posts(self):
|
||||
# This function only retrieves the first 10 note
|
||||
# And you can continue to make requests to obtain more by checking the boolean status of "has_more".
|
||||
print("Begin search xiaohongshu keywords: ", self.keywords)
|
||||
posts_res = await self.xhs_client.get_note_by_keyword(keyword=self.keywords)
|
||||
for post_item in posts_res.get("items"):
|
||||
note_id = post_item.get("id")
|
||||
title = post_item.get("note_card", {}).get("display_title")
|
||||
print(f"Note ID:{note_id}; Title:{title}")
|
||||
# todo record note or save to db or csv
|
||||
return posts_res
|
||||
|
||||
async def get_comments(self, note_id: str):
|
||||
# This function only retrieves the first 10 comments
|
||||
# And you can continue to make requests to obtain more by checking the boolean status of "has_more".
|
||||
print("Begin get note id comments ", note_id)
|
||||
res = await self.xhs_client.get_note_comments(note_id=note_id)
|
||||
# res = await self.xhs_client.get_note_all_comments(note_id=note_id)
|
||||
for comment in res.get("comments"):
|
||||
nick_name = comment.get("user_info").get("nickname")
|
||||
comment_content = comment.get("content")
|
||||
print(f"Nickname:{nick_name}; Comment content:{comment_content}")
|
||||
# todo save to db or csv
|
||||
return res
|
||||
|
|
@ -0,0 +1,9 @@
|
|||
from httpx import RequestError
|
||||
|
||||
|
||||
class DataFetchError(RequestError):
|
||||
"""something error when fetch"""
|
||||
|
||||
|
||||
class IPBlockError(RequestError):
|
||||
"""fetch so fast that the server block us ip"""
|
||||
|
|
@ -0,0 +1,72 @@
|
|||
from enum import Enum
|
||||
from typing import NamedTuple
|
||||
|
||||
|
||||
class FeedType(Enum):
|
||||
# 推荐
|
||||
RECOMMEND = "homefeed_recommend"
|
||||
# 穿搭
|
||||
FASION = "homefeed.fashion_v3"
|
||||
# 美食
|
||||
FOOD = "homefeed.food_v3"
|
||||
# 彩妆
|
||||
COSMETICS = "homefeed.cosmetics_v3"
|
||||
# 影视
|
||||
MOVIE = "homefeed.movie_and_tv_v3"
|
||||
# 职场
|
||||
CAREER = "homefeed.career_v3"
|
||||
# 情感
|
||||
EMOTION = "homefeed.love_v3"
|
||||
# 家居
|
||||
HOURSE = "homefeed.household_product_v3"
|
||||
# 游戏
|
||||
GAME = "homefeed.gaming_v3"
|
||||
# 旅行
|
||||
TRAVEL = "homefeed.travel_v3"
|
||||
# 健身
|
||||
FITNESS = "homefeed.fitness_v3"
|
||||
|
||||
|
||||
class NoteType(Enum):
|
||||
NOMAL = "nomal"
|
||||
VIDEO = "video"
|
||||
|
||||
|
||||
class SearchSortType(Enum):
|
||||
"""search sort type"""
|
||||
# default
|
||||
GENERAL = "general"
|
||||
# most popular
|
||||
MOST_POPULAR = "popularity_descending"
|
||||
# Latest
|
||||
LATEST = "time_descending"
|
||||
|
||||
|
||||
class SearchNoteType(Enum):
|
||||
"""search note type
|
||||
"""
|
||||
# default
|
||||
ALL = 0
|
||||
# only video
|
||||
VIDEO = 1
|
||||
# only image
|
||||
IMAGE = 2
|
||||
|
||||
|
||||
class Note(NamedTuple):
|
||||
"""note tuple"""
|
||||
note_id: str
|
||||
title: str
|
||||
desc: str
|
||||
type: str
|
||||
user: dict
|
||||
img_urls: list
|
||||
video_url: str
|
||||
tag_list: list
|
||||
at_user_list: list
|
||||
collected_count: str
|
||||
comment_count: str
|
||||
liked_count: str
|
||||
share_count: str
|
||||
time: int
|
||||
last_update_time: int
|
||||
|
|
@ -0,0 +1,262 @@
|
|||
import ctypes
|
||||
import json
|
||||
import random
|
||||
import time
|
||||
import urllib.parse
|
||||
|
||||
|
||||
def sign(a1="", b1="", x_s="", x_t=""):
|
||||
"""
|
||||
takes in a URI (uniform resource identifier), an optional data dictionary, and an optional ctime parameter. It returns a dictionary containing two keys: "x-s" and "x-t".
|
||||
"""
|
||||
common = {
|
||||
"s0": 5, # getPlatformCode
|
||||
"s1": "",
|
||||
"x0": "1", # localStorage.getItem("b1b1")
|
||||
"x1": "3.3.0", # version
|
||||
"x2": "Windows",
|
||||
"x3": "xhs-pc-web",
|
||||
"x4": "1.4.4",
|
||||
"x5": a1, # cookie of a1
|
||||
"x6": x_t,
|
||||
"x7": x_s,
|
||||
"x8": b1, # localStorage.getItem("b1")
|
||||
"x9": mrc(x_t + x_s + b1),
|
||||
"x10": 1, # getSigCount
|
||||
}
|
||||
encode_str = encodeUtf8(json.dumps(common, separators=(',', ':')))
|
||||
x_s_common = b64Encode(encode_str)
|
||||
x_b3_traceid = get_b3_trace_id()
|
||||
return {
|
||||
"x-s": x_s,
|
||||
"x-t": x_t,
|
||||
"x-s-common": x_s_common,
|
||||
"x-b3-traceid": x_b3_traceid
|
||||
}
|
||||
|
||||
|
||||
def get_b3_trace_id():
|
||||
re = "abcdef0123456789"
|
||||
je = 16
|
||||
e = ""
|
||||
for t in range(16):
|
||||
e += re[random.randint(0, je - 1)]
|
||||
return e
|
||||
|
||||
|
||||
def mrc(e):
|
||||
ie = [
|
||||
0, 1996959894, 3993919788, 2567524794, 124634137, 1886057615, 3915621685,
|
||||
2657392035, 249268274, 2044508324, 3772115230, 2547177864, 162941995,
|
||||
2125561021, 3887607047, 2428444049, 498536548, 1789927666, 4089016648,
|
||||
2227061214, 450548861, 1843258603, 4107580753, 2211677639, 325883990,
|
||||
1684777152, 4251122042, 2321926636, 335633487, 1661365465, 4195302755,
|
||||
2366115317, 997073096, 1281953886, 3579855332, 2724688242, 1006888145,
|
||||
1258607687, 3524101629, 2768942443, 901097722, 1119000684, 3686517206,
|
||||
2898065728, 853044451, 1172266101, 3705015759, 2882616665, 651767980,
|
||||
1373503546, 3369554304, 3218104598, 565507253, 1454621731, 3485111705,
|
||||
3099436303, 671266974, 1594198024, 3322730930, 2970347812, 795835527,
|
||||
1483230225, 3244367275, 3060149565, 1994146192, 31158534, 2563907772,
|
||||
4023717930, 1907459465, 112637215, 2680153253, 3904427059, 2013776290,
|
||||
251722036, 2517215374, 3775830040, 2137656763, 141376813, 2439277719,
|
||||
3865271297, 1802195444, 476864866, 2238001368, 4066508878, 1812370925,
|
||||
453092731, 2181625025, 4111451223, 1706088902, 314042704, 2344532202,
|
||||
4240017532, 1658658271, 366619977, 2362670323, 4224994405, 1303535960,
|
||||
984961486, 2747007092, 3569037538, 1256170817, 1037604311, 2765210733,
|
||||
3554079995, 1131014506, 879679996, 2909243462, 3663771856, 1141124467,
|
||||
855842277, 2852801631, 3708648649, 1342533948, 654459306, 3188396048,
|
||||
3373015174, 1466479909, 544179635, 3110523913, 3462522015, 1591671054,
|
||||
702138776, 2966460450, 3352799412, 1504918807, 783551873, 3082640443,
|
||||
3233442989, 3988292384, 2596254646, 62317068, 1957810842, 3939845945,
|
||||
2647816111, 81470997, 1943803523, 3814918930, 2489596804, 225274430,
|
||||
2053790376, 3826175755, 2466906013, 167816743, 2097651377, 4027552580,
|
||||
2265490386, 503444072, 1762050814, 4150417245, 2154129355, 426522225,
|
||||
1852507879, 4275313526, 2312317920, 282753626, 1742555852, 4189708143,
|
||||
2394877945, 397917763, 1622183637, 3604390888, 2714866558, 953729732,
|
||||
1340076626, 3518719985, 2797360999, 1068828381, 1219638859, 3624741850,
|
||||
2936675148, 906185462, 1090812512, 3747672003, 2825379669, 829329135,
|
||||
1181335161, 3412177804, 3160834842, 628085408, 1382605366, 3423369109,
|
||||
3138078467, 570562233, 1426400815, 3317316542, 2998733608, 733239954,
|
||||
1555261956, 3268935591, 3050360625, 752459403, 1541320221, 2607071920,
|
||||
3965973030, 1969922972, 40735498, 2617837225, 3943577151, 1913087877,
|
||||
83908371, 2512341634, 3803740692, 2075208622, 213261112, 2463272603,
|
||||
3855990285, 2094854071, 198958881, 2262029012, 4057260610, 1759359992,
|
||||
534414190, 2176718541, 4139329115, 1873836001, 414664567, 2282248934,
|
||||
4279200368, 1711684554, 285281116, 2405801727, 4167216745, 1634467795,
|
||||
376229701, 2685067896, 3608007406, 1308918612, 956543938, 2808555105,
|
||||
3495958263, 1231636301, 1047427035, 2932959818, 3654703836, 1088359270,
|
||||
936918000, 2847714899, 3736837829, 1202900863, 817233897, 3183342108,
|
||||
3401237130, 1404277552, 615818150, 3134207493, 3453421203, 1423857449,
|
||||
601450431, 3009837614, 3294710456, 1567103746, 711928724, 3020668471,
|
||||
3272380065, 1510334235, 755167117,
|
||||
]
|
||||
o = -1
|
||||
|
||||
def right_without_sign(num, bit=0) -> int:
|
||||
val = ctypes.c_uint32(num).value >> bit
|
||||
MAX32INT = 4294967295
|
||||
return (val + (MAX32INT + 1)) % (2 * (MAX32INT + 1)) - MAX32INT - 1
|
||||
|
||||
for n in range(57):
|
||||
o = ie[(o & 255) ^ ord(e[n])] ^ right_without_sign(o, 8)
|
||||
return o ^ -1 ^ 3988292384
|
||||
|
||||
|
||||
lookup = [
|
||||
"Z",
|
||||
"m",
|
||||
"s",
|
||||
"e",
|
||||
"r",
|
||||
"b",
|
||||
"B",
|
||||
"o",
|
||||
"H",
|
||||
"Q",
|
||||
"t",
|
||||
"N",
|
||||
"P",
|
||||
"+",
|
||||
"w",
|
||||
"O",
|
||||
"c",
|
||||
"z",
|
||||
"a",
|
||||
"/",
|
||||
"L",
|
||||
"p",
|
||||
"n",
|
||||
"g",
|
||||
"G",
|
||||
"8",
|
||||
"y",
|
||||
"J",
|
||||
"q",
|
||||
"4",
|
||||
"2",
|
||||
"K",
|
||||
"W",
|
||||
"Y",
|
||||
"j",
|
||||
"0",
|
||||
"D",
|
||||
"S",
|
||||
"f",
|
||||
"d",
|
||||
"i",
|
||||
"k",
|
||||
"x",
|
||||
"3",
|
||||
"V",
|
||||
"T",
|
||||
"1",
|
||||
"6",
|
||||
"I",
|
||||
"l",
|
||||
"U",
|
||||
"A",
|
||||
"F",
|
||||
"M",
|
||||
"9",
|
||||
"7",
|
||||
"h",
|
||||
"E",
|
||||
"C",
|
||||
"v",
|
||||
"u",
|
||||
"R",
|
||||
"X",
|
||||
"5",
|
||||
]
|
||||
|
||||
|
||||
def tripletToBase64(e):
|
||||
return (
|
||||
lookup[63 & (e >> 18)] +
|
||||
lookup[63 & (e >> 12)] +
|
||||
lookup[(e >> 6) & 63] +
|
||||
lookup[e & 63]
|
||||
)
|
||||
|
||||
|
||||
def encodeChunk(e, t, r):
|
||||
m = []
|
||||
for b in range(t, r, 3):
|
||||
n = (16711680 & (e[b] << 16)) + \
|
||||
((e[b + 1] << 8) & 65280) + (e[b + 2] & 255)
|
||||
m.append(tripletToBase64(n))
|
||||
return ''.join(m)
|
||||
|
||||
|
||||
def b64Encode(e):
|
||||
P = len(e)
|
||||
W = P % 3
|
||||
U = []
|
||||
z = 16383
|
||||
H = 0
|
||||
Z = P - W
|
||||
while H < Z:
|
||||
U.append(encodeChunk(e, H, Z if H + z > Z else H + z))
|
||||
H += z
|
||||
if 1 == W:
|
||||
F = e[P - 1]
|
||||
U.append(lookup[F >> 2] + lookup[(F << 4) & 63] + "==")
|
||||
elif 2 == W:
|
||||
F = (e[P - 2] << 8) + e[P - 1]
|
||||
U.append(lookup[F >> 10] + lookup[63 & (F >> 4)] +
|
||||
lookup[(F << 2) & 63] + "=")
|
||||
return "".join(U)
|
||||
|
||||
|
||||
def encodeUtf8(e):
|
||||
b = []
|
||||
m = urllib.parse.quote(e, safe='~()*!.\'')
|
||||
w = 0
|
||||
while w < len(m):
|
||||
T = m[w]
|
||||
if T == "%":
|
||||
E = m[w + 1] + m[w + 2]
|
||||
S = int(E, 16)
|
||||
b.append(S)
|
||||
w += 2
|
||||
else:
|
||||
b.append(ord(T[0]))
|
||||
w += 1
|
||||
return b
|
||||
|
||||
|
||||
def base36encode(number, alphabet='0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'):
|
||||
"""Converts an integer to a base36 string."""
|
||||
if not isinstance(number, int):
|
||||
raise TypeError('number must be an integer')
|
||||
|
||||
base36 = ''
|
||||
sign = ''
|
||||
|
||||
if number < 0:
|
||||
sign = '-'
|
||||
number = -number
|
||||
|
||||
if 0 <= number < len(alphabet):
|
||||
return sign + alphabet[number]
|
||||
|
||||
while number != 0:
|
||||
number, i = divmod(number, len(alphabet))
|
||||
base36 = alphabet[i] + base36
|
||||
|
||||
return sign + base36
|
||||
|
||||
|
||||
def base36decode(number):
|
||||
return int(number, 36)
|
||||
|
||||
|
||||
def get_search_id():
|
||||
e = int(time.time() * 1000) << 64
|
||||
t = int(random.uniform(0, 2147483646))
|
||||
return base36encode((e + t))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
a = get_b3_trace_id()
|
||||
print(a)
|
||||
|
|
@ -0,0 +1,3 @@
|
|||
httpx==0.24.0
|
||||
Pillow==9.5.0
|
||||
playwright==1.33.0
|
||||
|
|
@ -0,0 +1,55 @@
|
|||
import json
|
||||
import time
|
||||
import base64
|
||||
import random
|
||||
import hashlib
|
||||
from io import BytesIO
|
||||
from typing import Optional, Dict, List, Tuple
|
||||
|
||||
from PIL import Image
|
||||
from playwright.async_api import Cookie
|
||||
from playwright.async_api import Page
|
||||
|
||||
|
||||
async def find_login_qrcode(page: Page, selector: str) -> str:
|
||||
"""find login qrcode image from target selector"""
|
||||
try:
|
||||
elements = await page.wait_for_selector(
|
||||
selector=selector,
|
||||
)
|
||||
login_qrcode_img = await elements.get_property("src")
|
||||
return str(login_qrcode_img)
|
||||
|
||||
except Exception as e:
|
||||
print(e)
|
||||
return ""
|
||||
|
||||
|
||||
def show_qrcode(qr_code: str):
|
||||
"""parse base64 encode qrcode image and show it"""
|
||||
qr_code = qr_code.split(",")[1]
|
||||
qr_code = base64.b64decode(qr_code)
|
||||
image = Image.open(BytesIO(qr_code))
|
||||
image.show()
|
||||
|
||||
|
||||
def get_user_agent() -> str:
|
||||
ua_list = [
|
||||
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
|
||||
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.79 Safari/537.36",
|
||||
"Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36",
|
||||
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36",
|
||||
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36",
|
||||
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
|
||||
]
|
||||
return random.choice(ua_list)
|
||||
|
||||
|
||||
def convert_cookies(cookies: Optional[List[Cookie]]) -> Tuple[str, Dict]:
|
||||
if not cookies:
|
||||
return "", {}
|
||||
cookies_str = ";".join([f"{cookie.get('name')}={cookie.get('value')}" for cookie in cookies])
|
||||
cookie_dict = dict()
|
||||
for cookie in cookies:
|
||||
cookie_dict[cookie.get('name')] = cookie.get('value')
|
||||
return cookies_str, cookie_dict
|
||||
Loading…
Reference in New Issue