feat: 抖音评论done
This commit is contained in:
parent
aefdca6f7c
commit
a7c7f9533d
|
|
@ -11,9 +11,9 @@
|
||||||
|
|
||||||
## 主要功能
|
## 主要功能
|
||||||
- [x] 小红书 笔记、评论
|
- [x] 小红书 笔记、评论
|
||||||
- [x] 二维码扫描登录 | 手机号+验证码自动登录 | web_session
|
- [x] 小红书 二维码扫描登录 | 手机号+验证码自动登录 | cookies登录
|
||||||
|
- [x] 爬取抖音视频、评论
|
||||||
- [ ] To do 抖音滑块
|
- [ ] To do 抖音滑块
|
||||||
- [ ] To do 爬取抖音视频、评论
|
|
||||||
|
|
||||||
## 技术栈
|
## 技术栈
|
||||||
|
|
||||||
|
|
@ -35,7 +35,7 @@
|
||||||
|

|
||||||
|
|
||||||
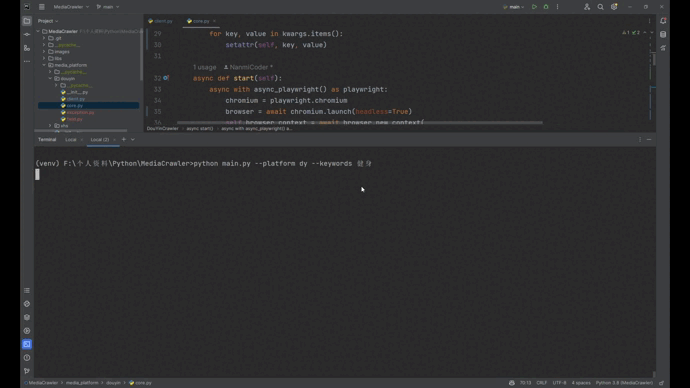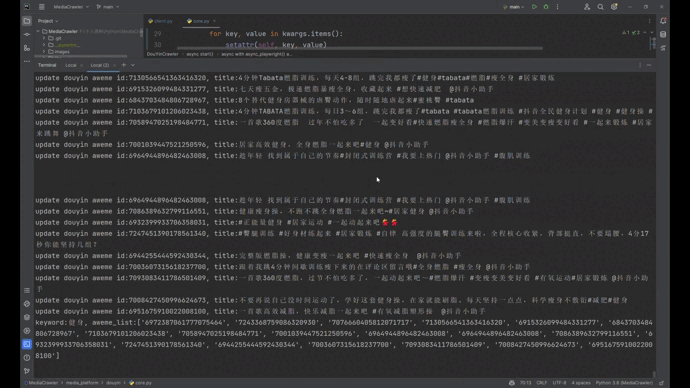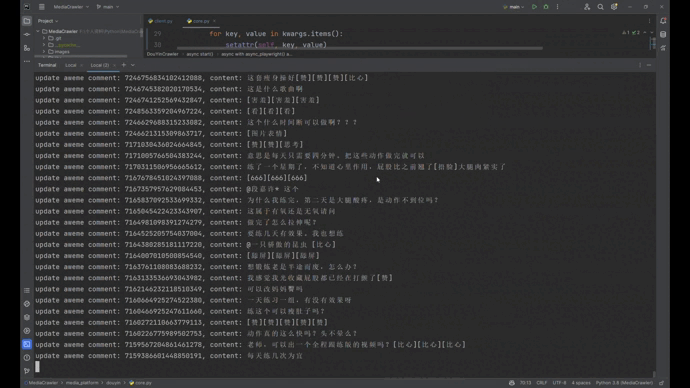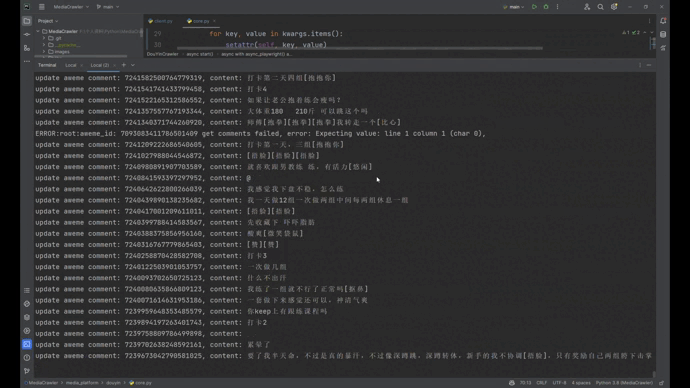
## 抖音运行截图
|
## 抖音运行截图
|
||||||
- [ ] To do
|
- 
|
||||||
|
|
||||||
## 关于手机号+验证码登录的说明
|
## 关于手机号+验证码登录的说明
|
||||||
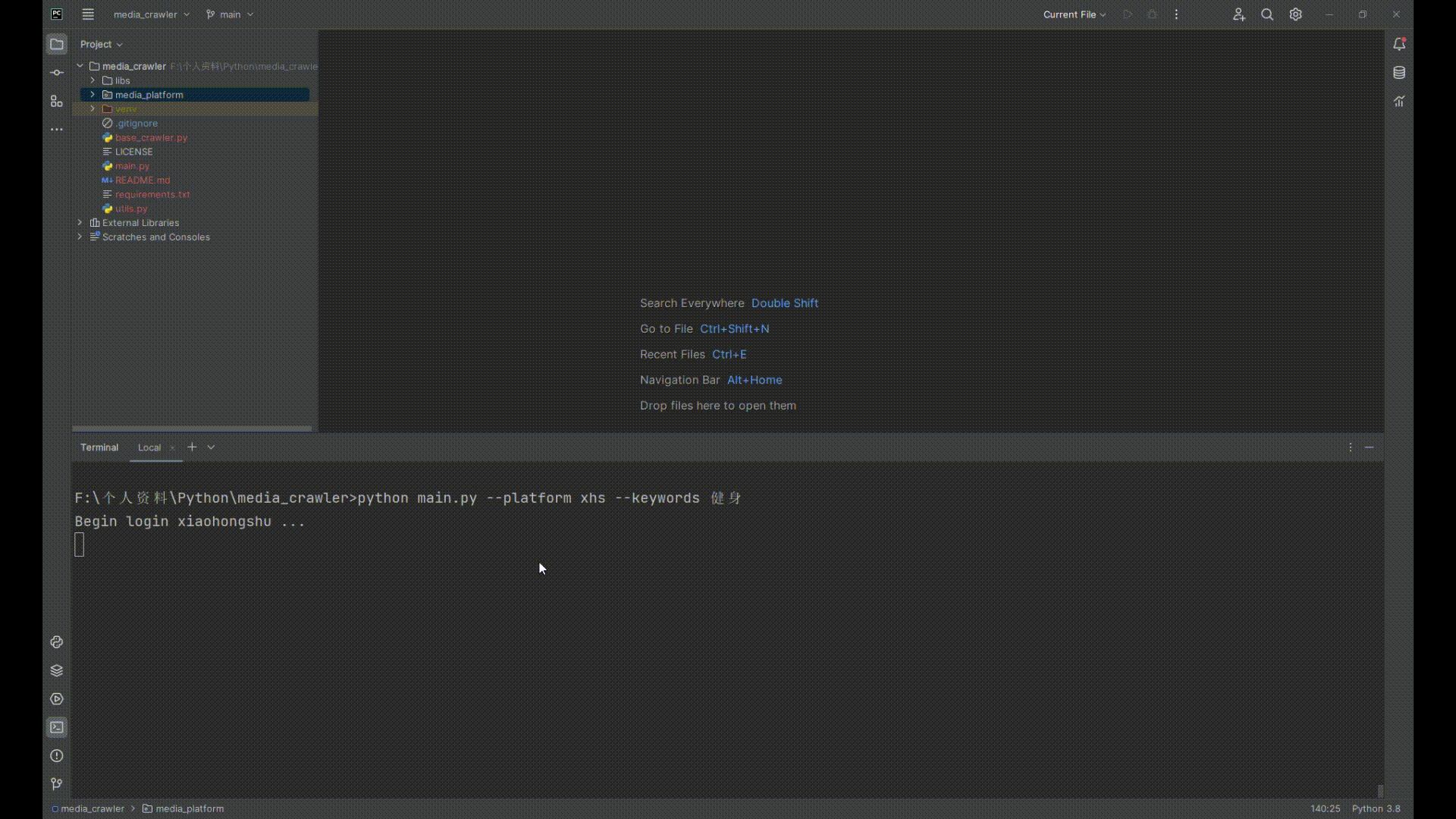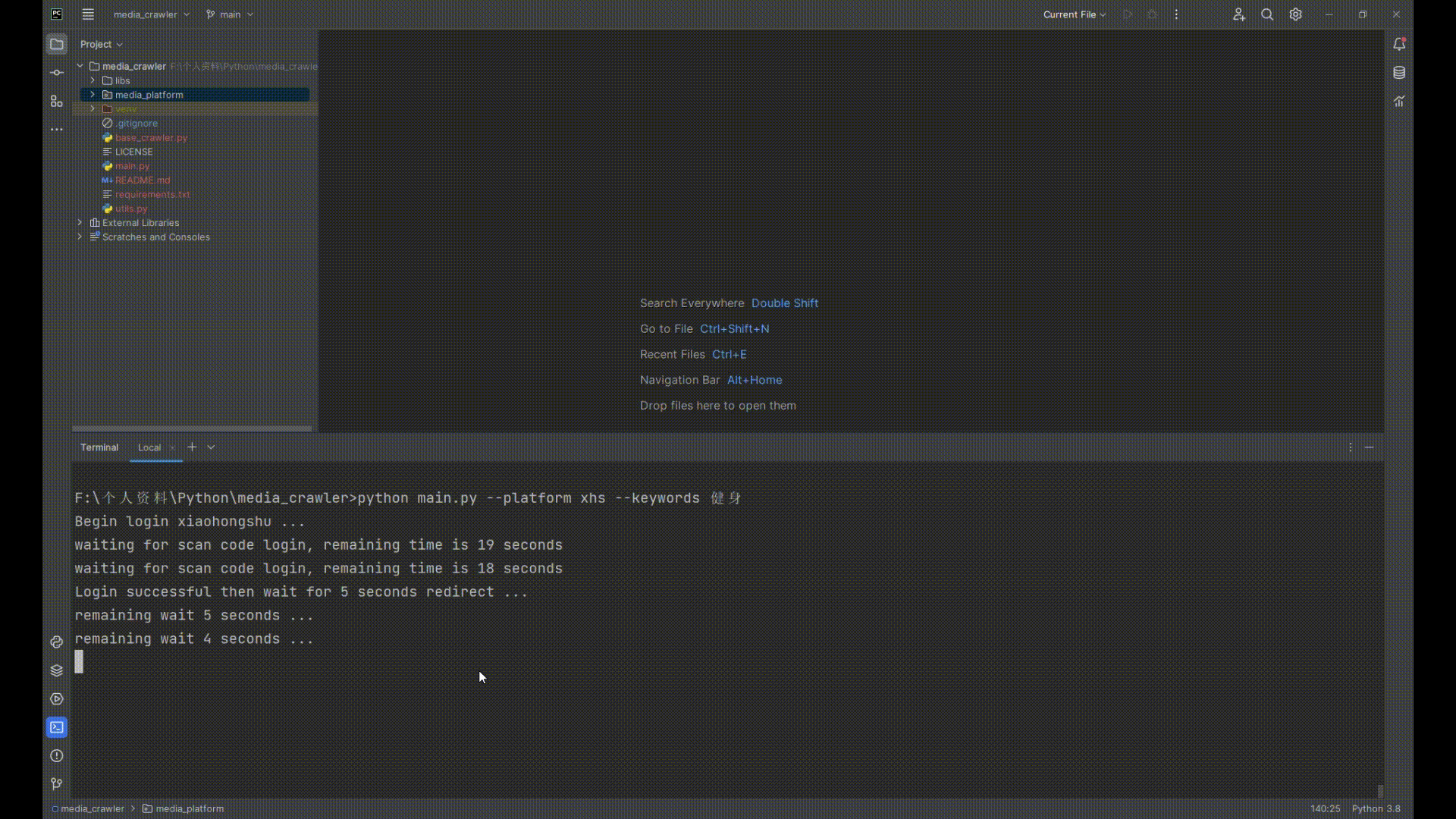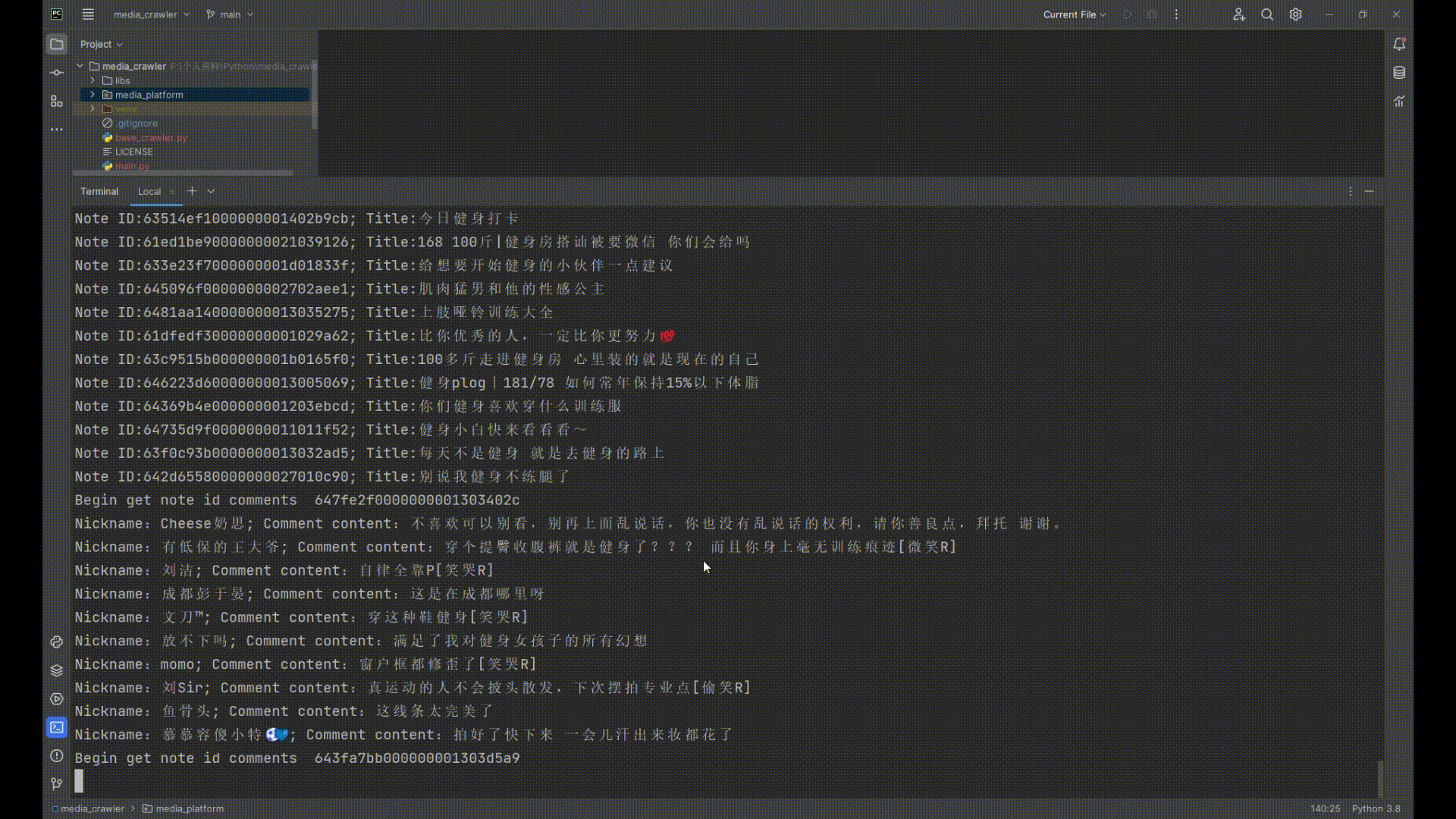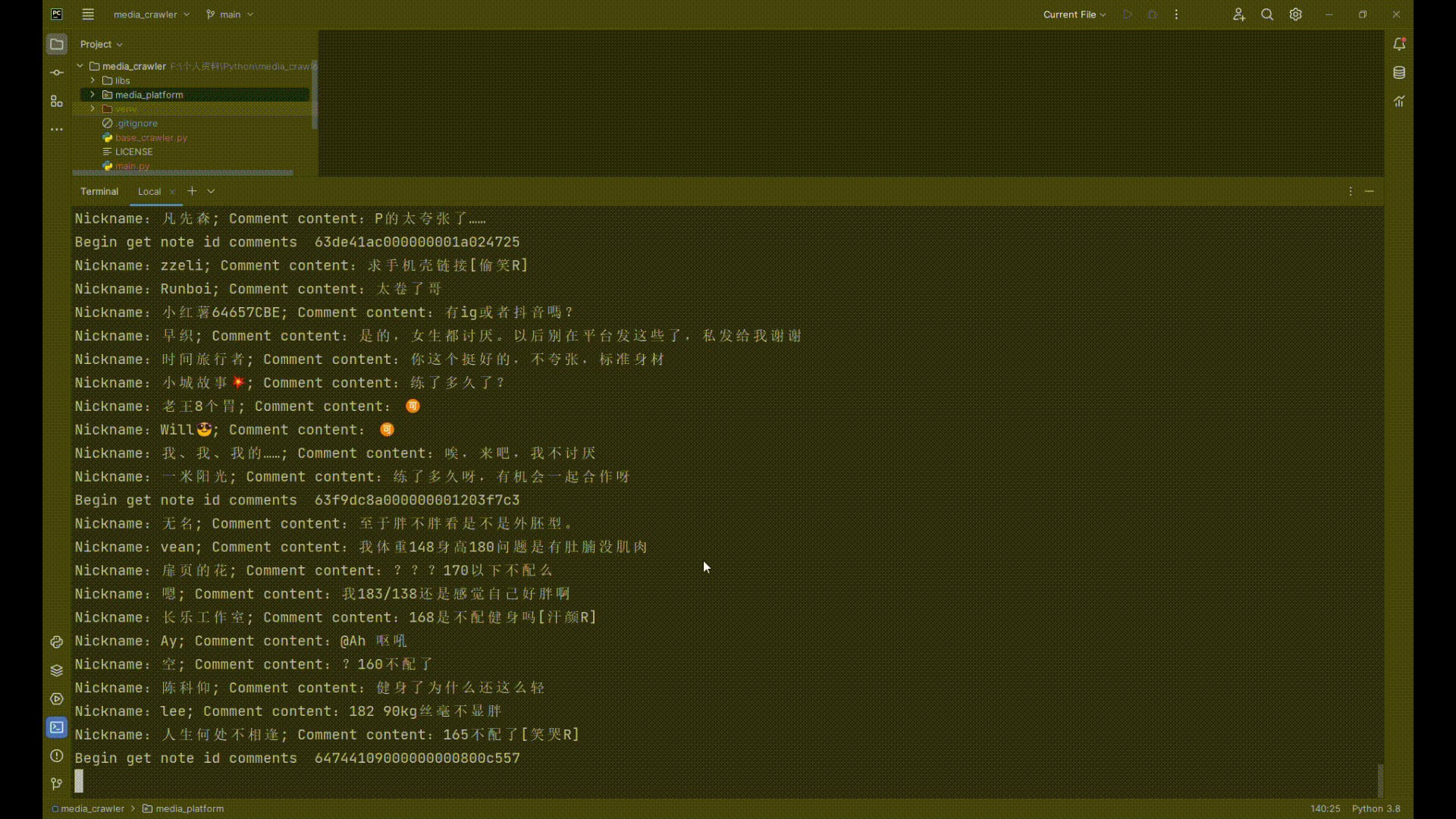
当在小红书等平台上使用手机登录时,发送验证码后,使用短信转发器完成验证码转发。
|
当在小红书等平台上使用手机登录时,发送验证码后,使用短信转发器完成验证码转发。
|
||||||
|
|
|
||||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 2.4 MiB |
|
|
@ -1,13 +1,20 @@
|
||||||
from typing import Optional, Dict
|
import copy
|
||||||
|
import asyncio
|
||||||
|
from typing import Optional, Dict, Callable
|
||||||
|
|
||||||
import httpx
|
import httpx
|
||||||
|
import execjs
|
||||||
|
import urllib.parse
|
||||||
from playwright.async_api import Page
|
from playwright.async_api import Page
|
||||||
|
|
||||||
|
from .field import *
|
||||||
|
from .exception import *
|
||||||
|
|
||||||
|
|
||||||
class DOUYINClient:
|
class DOUYINClient:
|
||||||
def __init__(
|
def __init__(
|
||||||
self,
|
self,
|
||||||
timeout=10,
|
timeout=30,
|
||||||
proxies=None,
|
proxies=None,
|
||||||
headers: Optional[Dict] = None,
|
headers: Optional[Dict] = None,
|
||||||
playwright_page: Page = None,
|
playwright_page: Page = None,
|
||||||
|
|
@ -20,8 +27,39 @@ class DOUYINClient:
|
||||||
self.playwright_page = playwright_page
|
self.playwright_page = playwright_page
|
||||||
self.cookie_dict = cookie_dict
|
self.cookie_dict = cookie_dict
|
||||||
|
|
||||||
async def _pre_params(self, url: str, data=None):
|
async def __process_req_params(self, params: Optional[Dict] = None, headers: Optional[Dict] = None):
|
||||||
pass
|
if not params:
|
||||||
|
return
|
||||||
|
headers = headers or self.headers
|
||||||
|
local_storage: Dict = await self.playwright_page.evaluate("() => window.localStorage")
|
||||||
|
douyin_js_obj = execjs.compile(open('libs/douyin.js').read())
|
||||||
|
# douyin_js_obj = execjs.compile(open('libs/X-Bogus.js').read())
|
||||||
|
common_params = {
|
||||||
|
"device_platform": "webapp",
|
||||||
|
"aid": "6383",
|
||||||
|
"channel": "channel_pc_web",
|
||||||
|
"cookie_enabled": "true",
|
||||||
|
"browser_language": "zh-CN",
|
||||||
|
"browser_platform": "Win32",
|
||||||
|
"browser_name": "Firefox",
|
||||||
|
"browser_version": "110.0",
|
||||||
|
"browser_online": "true",
|
||||||
|
"engine_name": "Gecko",
|
||||||
|
"os_name": "Windows",
|
||||||
|
"os_version": "10",
|
||||||
|
"engine_version": "109.0",
|
||||||
|
"platform": "PC",
|
||||||
|
"screen_width": "1920",
|
||||||
|
"screen_height": "1200",
|
||||||
|
"webid": douyin_js_obj.call("get_web_id"),
|
||||||
|
"msToken": local_storage.get("xmst"),
|
||||||
|
# "msToken": "abL8SeUTPa9-EToD8qfC7toScSADxpg6yLh2dbNcpWHzE0bT04txM_4UwquIcRvkRb9IU8sifwgM1Kwf1Lsld81o9Irt2_yNyUbbQPSUO8EfVlZJ_78FckDFnwVBVUVK",
|
||||||
|
}
|
||||||
|
params.update(common_params)
|
||||||
|
query = '&'.join([f'{k}={v}' for k, v in params.items()])
|
||||||
|
x_bogus = douyin_js_obj.call('sign', query, headers["User-Agent"])
|
||||||
|
params["X-Bogus"] = x_bogus
|
||||||
|
# print(x_bogus, query)
|
||||||
|
|
||||||
async def request(self, method, url, **kwargs):
|
async def request(self, method, url, **kwargs):
|
||||||
async with httpx.AsyncClient(proxies=self.proxies) as client:
|
async with httpx.AsyncClient(proxies=self.proxies) as client:
|
||||||
|
|
@ -29,14 +67,111 @@ class DOUYINClient:
|
||||||
method, url, timeout=self.timeout,
|
method, url, timeout=self.timeout,
|
||||||
**kwargs
|
**kwargs
|
||||||
)
|
)
|
||||||
data = response.json()
|
try:
|
||||||
if data["success"]:
|
return response.json()
|
||||||
return data.get("data", data.get("success"))
|
except Exception as e:
|
||||||
else:
|
raise DataFetchError(f"{e}, {response.text}")
|
||||||
pass
|
|
||||||
|
|
||||||
async def get(self, uri: str, params=None):
|
async def get(self, uri: str, params: Optional[Dict] = None, headers: Optional[Dict] = None):
|
||||||
pass
|
await self.__process_req_params(params, headers)
|
||||||
|
headers = headers or self.headers
|
||||||
|
return await self.request(method="GET", url=f"{self._host}{uri}", params=params, headers=headers)
|
||||||
|
|
||||||
async def post(self, uri: str, data: dict):
|
async def post(self, uri: str, data: dict, headers: Optional[Dict] = None):
|
||||||
pass
|
await self.__process_req_params(data, headers)
|
||||||
|
headers = headers or self.headers
|
||||||
|
return await self.request(method="POST", url=f"{self._host}{uri}", data=data, headers=headers)
|
||||||
|
|
||||||
|
async def search_info_by_keyword(
|
||||||
|
self,
|
||||||
|
keyword: str,
|
||||||
|
offset: int = 0,
|
||||||
|
search_channel: SearchChannelType = SearchChannelType.GENERAL,
|
||||||
|
sort_type: SearchSortType = SearchSortType.GENERAL,
|
||||||
|
publish_time: PublishTimeType = PublishTimeType.UNLIMITED
|
||||||
|
):
|
||||||
|
"""
|
||||||
|
DouYin Web Search API
|
||||||
|
:param keyword:
|
||||||
|
:param offset:
|
||||||
|
:param search_channel:
|
||||||
|
:param sort_type:
|
||||||
|
:param publish_time: ·
|
||||||
|
:return:
|
||||||
|
"""
|
||||||
|
params = {
|
||||||
|
"keyword": keyword,
|
||||||
|
"search_channel": search_channel.value,
|
||||||
|
"sort_type": sort_type.value,
|
||||||
|
"publish_time": publish_time.value,
|
||||||
|
"search_source": "normal_search",
|
||||||
|
"query_correct_type": "1",
|
||||||
|
"is_filter_search": "0",
|
||||||
|
"offset": offset,
|
||||||
|
"count": 10 # must be set to 10
|
||||||
|
}
|
||||||
|
referer_url = "https://www.douyin.com/search/" + keyword
|
||||||
|
headers = copy.copy(self.headers)
|
||||||
|
headers["Referer"] = urllib.parse.quote(referer_url, safe=':/')
|
||||||
|
return await self.get("/aweme/v1/web/general/search/single/", params, headers=headers)
|
||||||
|
|
||||||
|
async def get_video_by_id(self, aweme_id: str):
|
||||||
|
"""
|
||||||
|
DouYin Video Detail API
|
||||||
|
:param aweme_id:
|
||||||
|
:return:
|
||||||
|
"""
|
||||||
|
params = {
|
||||||
|
"aweme_id": aweme_id
|
||||||
|
}
|
||||||
|
headers = copy.copy(self.headers)
|
||||||
|
headers["Cookie"] = "s_v_web_id=verify_leytkxgn_kvO5kOmO_SdMs_4t1o_B5ml_BUqtWM1mP6BF;"
|
||||||
|
del headers["Origin"]
|
||||||
|
return await self.get("/aweme/v1/web/aweme/detail/", params, headers)
|
||||||
|
|
||||||
|
async def get_aweme_comments(self, aweme_id: str, cursor: str = ""):
|
||||||
|
"""get note comments
|
||||||
|
|
||||||
|
"""
|
||||||
|
uri = "/aweme/v1/web/comment/list/"
|
||||||
|
params = {
|
||||||
|
"aweme_id": aweme_id,
|
||||||
|
"cursor": cursor,
|
||||||
|
"count": 20,
|
||||||
|
"item_type": 0
|
||||||
|
}
|
||||||
|
return await self.get(uri, params)
|
||||||
|
|
||||||
|
async def get_aweme_all_comments(
|
||||||
|
self,
|
||||||
|
aweme_id: str,
|
||||||
|
crawl_interval: float = 1.0,
|
||||||
|
is_fetch_sub_comments=False,
|
||||||
|
callback: Optional[Callable] = None
|
||||||
|
):
|
||||||
|
"""
|
||||||
|
get note all comments include sub comments
|
||||||
|
:param aweme_id:
|
||||||
|
:param crawl_interval:
|
||||||
|
:param is_fetch_sub_comments:
|
||||||
|
:param callback:
|
||||||
|
:return:
|
||||||
|
"""
|
||||||
|
result = []
|
||||||
|
comments_has_more = 1
|
||||||
|
comments_cursor = 0
|
||||||
|
while comments_has_more:
|
||||||
|
comments_res = await self.get_aweme_comments(aweme_id, comments_cursor)
|
||||||
|
comments_has_more = comments_res.get("has_more", 0)
|
||||||
|
comments_cursor = comments_res.get("cursor", comments_cursor + 20)
|
||||||
|
comments = comments_res.get("comments")
|
||||||
|
if not comments:
|
||||||
|
continue
|
||||||
|
if callback: # 如果有回调函数,就执行回调函数
|
||||||
|
await callback(aweme_id, comments)
|
||||||
|
await asyncio.sleep(crawl_interval)
|
||||||
|
if not is_fetch_sub_comments:
|
||||||
|
result.extend(comments)
|
||||||
|
continue
|
||||||
|
# todo fetch sub comments
|
||||||
|
return result
|
||||||
|
|
|
||||||
|
|
@ -1,5 +1,6 @@
|
||||||
import sys
|
import logging
|
||||||
import asyncio
|
import asyncio
|
||||||
|
from asyncio import Task
|
||||||
from typing import Optional, List, Dict
|
from typing import Optional, List, Dict
|
||||||
|
|
||||||
from playwright.async_api import async_playwright
|
from playwright.async_api import async_playwright
|
||||||
|
|
@ -9,42 +10,63 @@ from playwright.async_api import BrowserContext
|
||||||
|
|
||||||
import utils
|
import utils
|
||||||
from .client import DOUYINClient
|
from .client import DOUYINClient
|
||||||
|
from .exception import DataFetchError
|
||||||
from base_crawler import Crawler
|
from base_crawler import Crawler
|
||||||
|
from models import douyin
|
||||||
|
|
||||||
|
|
||||||
class DouYinCrawler(Crawler):
|
class DouYinCrawler(Crawler):
|
||||||
def __init__(self):
|
def __init__(self):
|
||||||
self.keywords: Optional[str] = None
|
self.keywords: Optional[str] = None
|
||||||
self.scan_qrcode_time: Optional[int] = None
|
|
||||||
self.cookies: Optional[List[Cookie]] = None
|
self.cookies: Optional[List[Cookie]] = None
|
||||||
self.browser_context: Optional[BrowserContext] = None
|
self.browser_context: Optional[BrowserContext] = None
|
||||||
self.context_page: Optional[Page] = None
|
self.context_page: Optional[Page] = None
|
||||||
self.proxy: Optional[Dict] = None
|
self.proxy: Optional[Dict] = None
|
||||||
self.user_agent = utils.get_user_agent()
|
self.user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36" # fixed
|
||||||
self.dy_client: Optional[DOUYINClient] = None
|
self.dy_client: Optional[DOUYINClient] = None
|
||||||
|
|
||||||
def init_config(self, **kwargs):
|
def init_config(self, **kwargs):
|
||||||
self.keywords = kwargs.get("keywords")
|
for key, value in kwargs.items():
|
||||||
self.scan_qrcode_time = kwargs.get("scan_qrcode_time")
|
setattr(self, key, value)
|
||||||
|
|
||||||
async def start(self):
|
async def start(self):
|
||||||
async with async_playwright() as playwright:
|
async with async_playwright() as playwright:
|
||||||
chromium = playwright.chromium
|
chromium = playwright.chromium
|
||||||
browser = await chromium.launch(headless=False)
|
browser = await chromium.launch(headless=True)
|
||||||
self.browser_context = await browser.new_context(
|
self.browser_context = await browser.new_context(
|
||||||
viewport={"width": 1920, "height": 1080},
|
viewport={"width": 1800, "height": 900},
|
||||||
user_agent=self.user_agent,
|
user_agent=self.user_agent,
|
||||||
proxy=self.proxy
|
proxy=self.proxy
|
||||||
)
|
)
|
||||||
# execute JS to bypass anti automation/crawler detection
|
# execute JS to bypass anti automation/crawler detection
|
||||||
await self.browser_context.add_init_script(path="libs/stealth.min.js")
|
await self.browser_context.add_init_script(path="libs/stealth.min.js")
|
||||||
self.context_page = await self.browser_context.new_page()
|
self.context_page = await self.browser_context.new_page()
|
||||||
await self.context_page.goto("https://www.douyin.com")
|
await self.context_page.goto("https://www.douyin.com", wait_until="domcontentloaded")
|
||||||
|
await asyncio.sleep(3)
|
||||||
|
|
||||||
# scan qrcode login
|
# scan qrcode login
|
||||||
await self.login()
|
# await self.login()
|
||||||
await self.update_cookies()
|
await self.update_cookies()
|
||||||
|
|
||||||
|
# init request client
|
||||||
|
cookie_str, cookie_dict = utils.convert_cookies(self.cookies)
|
||||||
|
self.dy_client = DOUYINClient(
|
||||||
|
proxies=self.proxy,
|
||||||
|
headers={
|
||||||
|
"User-Agent": self.user_agent,
|
||||||
|
"Cookie": cookie_str,
|
||||||
|
"Host": "www.douyin.com",
|
||||||
|
"Origin": "https://www.douyin.com/",
|
||||||
|
"Referer": "https://www.douyin.com/",
|
||||||
|
"Content-Type": "application/json;charset=UTF-8"
|
||||||
|
},
|
||||||
|
playwright_page=self.context_page,
|
||||||
|
cookie_dict=cookie_dict,
|
||||||
|
)
|
||||||
|
|
||||||
|
# search_posts
|
||||||
|
await self.search_posts()
|
||||||
|
|
||||||
# block main crawler coroutine
|
# block main crawler coroutine
|
||||||
await asyncio.Event().wait()
|
await asyncio.Event().wait()
|
||||||
|
|
||||||
|
|
@ -52,10 +74,57 @@ class DouYinCrawler(Crawler):
|
||||||
self.cookies = await self.browser_context.cookies()
|
self.cookies = await self.browser_context.cookies()
|
||||||
|
|
||||||
async def login(self):
|
async def login(self):
|
||||||
pass
|
"""login douyin website and keep webdriver login state"""
|
||||||
|
print("Begin login douyin ...")
|
||||||
|
# todo ...
|
||||||
|
|
||||||
def search_posts(self):
|
async def check_login_state(self) -> bool:
|
||||||
pass
|
"""Check if the current login status is successful and return True otherwise return False"""
|
||||||
|
current_cookie = await self.browser_context.cookies()
|
||||||
|
_, cookie_dict = utils.convert_cookies(current_cookie)
|
||||||
|
if cookie_dict.get("LOGIN_STATUS") == "1":
|
||||||
|
return True
|
||||||
|
return False
|
||||||
|
|
||||||
def get_comments(self, item_id: str):
|
async def search_posts(self):
|
||||||
pass
|
# It is possible to modify the source code to allow for the passing of a batch of keywords.
|
||||||
|
for keyword in [self.keywords]:
|
||||||
|
print("Begin search douyin keywords: ", keyword)
|
||||||
|
aweme_list: List[str] = []
|
||||||
|
max_note_len = 20
|
||||||
|
page = 0
|
||||||
|
while max_note_len > 0:
|
||||||
|
try:
|
||||||
|
posts_res = await self.dy_client.search_info_by_keyword(keyword=keyword, offset=page * 10)
|
||||||
|
except DataFetchError:
|
||||||
|
logging.error(f"search douyin keyword: {keyword} failed")
|
||||||
|
break
|
||||||
|
page += 1
|
||||||
|
max_note_len -= 10
|
||||||
|
for post_item in posts_res.get("data"):
|
||||||
|
try:
|
||||||
|
aweme_info: Dict = post_item.get("aweme_info") or \
|
||||||
|
post_item.get("aweme_mix_info", {}).get("mix_items")[0]
|
||||||
|
except TypeError:
|
||||||
|
continue
|
||||||
|
aweme_list.append(aweme_info.get("aweme_id"))
|
||||||
|
await douyin.update_douyin_aweme(aweme_item=aweme_info)
|
||||||
|
print(f"keyword:{keyword}, aweme_list:{aweme_list}")
|
||||||
|
await self.batch_get_note_comments(aweme_list)
|
||||||
|
|
||||||
|
async def batch_get_note_comments(self, aweme_list: List[str]):
|
||||||
|
task_list: List[Task] = []
|
||||||
|
for aweme_id in aweme_list:
|
||||||
|
task = asyncio.create_task(self.get_comments(aweme_id), name=aweme_id)
|
||||||
|
task_list.append(task)
|
||||||
|
await asyncio.wait(task_list)
|
||||||
|
|
||||||
|
async def get_comments(self, aweme_id: str):
|
||||||
|
try:
|
||||||
|
await self.dy_client.get_aweme_all_comments(
|
||||||
|
aweme_id=aweme_id,
|
||||||
|
callback=douyin.batch_update_dy_aweme_comments
|
||||||
|
)
|
||||||
|
print(f"aweme_id: {aweme_id} comments have all been obtained completed ...")
|
||||||
|
except DataFetchError as e:
|
||||||
|
logging.error(f"aweme_id: {aweme_id} get comments failed, error: {e}")
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,9 @@
|
||||||
|
from httpx import RequestError
|
||||||
|
|
||||||
|
|
||||||
|
class DataFetchError(RequestError):
|
||||||
|
"""something error when fetch"""
|
||||||
|
|
||||||
|
|
||||||
|
class IPBlockError(RequestError):
|
||||||
|
"""fetch so fast that the server block us ip"""
|
||||||
|
|
@ -0,0 +1,24 @@
|
||||||
|
from enum import Enum
|
||||||
|
|
||||||
|
|
||||||
|
class SearchChannelType(Enum):
|
||||||
|
"""search channel type"""
|
||||||
|
GENERAL = "aweme_general" # 综合
|
||||||
|
VIDEO = "aweme_video_web" # 视频
|
||||||
|
USER = "aweme_user_web" # 用户
|
||||||
|
LIVE = "aweme_live" # 直播
|
||||||
|
|
||||||
|
|
||||||
|
class SearchSortType(Enum):
|
||||||
|
"""search sort type"""
|
||||||
|
GENERAL = 0 # 综合排序
|
||||||
|
LATEST = 1 # 最新发布
|
||||||
|
MOST_LIKE = 2 # 最多点赞
|
||||||
|
|
||||||
|
|
||||||
|
class PublishTimeType(Enum):
|
||||||
|
"""publish time type"""
|
||||||
|
UNLIMITED = 0 # 不限
|
||||||
|
ONE_DAY = 1 # 一天内
|
||||||
|
ONE_WEEK = 2 # 一周内
|
||||||
|
SIX_MONTH = 3 # 半年内
|
||||||
|
|
@ -0,0 +1 @@
|
||||||
|
from .m_douyin import *
|
||||||
|
|
@ -0,0 +1,64 @@
|
||||||
|
import json
|
||||||
|
from typing import Dict, List
|
||||||
|
|
||||||
|
import utils
|
||||||
|
|
||||||
|
|
||||||
|
async def update_douyin_aweme(aweme_item: Dict):
|
||||||
|
aweme_id = aweme_item.get("aweme_id")
|
||||||
|
user_info = aweme_item.get("author", {})
|
||||||
|
local_db_item = {
|
||||||
|
"aweme_id": aweme_id,
|
||||||
|
"aweme_type": aweme_item.get("aweme_type"),
|
||||||
|
"title": aweme_item.get("desc", ""),
|
||||||
|
"desc": aweme_item.get("desc", ""),
|
||||||
|
"create_time": aweme_item.get("create_time"),
|
||||||
|
"user_id": user_info.get("uid"),
|
||||||
|
"sec_uid": user_info.get("sec_uid"),
|
||||||
|
"short_user_id": user_info.get("short_id"),
|
||||||
|
"user_unique_id": user_info.get("unique_id"),
|
||||||
|
"user_signature": user_info.get("signature"),
|
||||||
|
"nickname": user_info.get("nickname"),
|
||||||
|
"avatar": user_info.get("avatar_thumb", {}).get("url_list", [""])[0],
|
||||||
|
"ip_location": aweme_item.get("ip_label", ""),
|
||||||
|
"last_modify_ts": utils.get_current_timestamp(),
|
||||||
|
}
|
||||||
|
# do something ...
|
||||||
|
print(f"update douyin aweme id:{aweme_id}, title:{local_db_item.get('title')}")
|
||||||
|
|
||||||
|
|
||||||
|
async def batch_update_dy_aweme_comments(aweme_id: str, comments: List[Dict]):
|
||||||
|
if not comments:
|
||||||
|
return
|
||||||
|
for comment_item in comments:
|
||||||
|
await update_dy_aweme_comment(aweme_id, comment_item)
|
||||||
|
|
||||||
|
|
||||||
|
async def update_dy_aweme_comment(aweme_id: str, comment_item: Dict):
|
||||||
|
comment_aweme_id = comment_item.get("aweme_id")
|
||||||
|
if aweme_id != comment_aweme_id:
|
||||||
|
print(f"comment_aweme_id: {comment_aweme_id} != aweme_id: {aweme_id}")
|
||||||
|
return
|
||||||
|
user_info = comment_item.get("user")
|
||||||
|
comment_id = comment_item.get("cid")
|
||||||
|
avatar_info = user_info.get("avatar_medium") or user_info.get("avatar_300x300") or user_info.get(
|
||||||
|
"avatar_168x168") or user_info.get("avatar_thumb") or {}
|
||||||
|
local_db_item = {
|
||||||
|
"comment_id": comment_id,
|
||||||
|
"create_time": comment_item.get("create_time"),
|
||||||
|
"ip_location": comment_item.get("ip_label", ""),
|
||||||
|
"aweme_id": aweme_id,
|
||||||
|
"content": comment_item.get("text"),
|
||||||
|
"content_extra": json.dumps(comment_item.get("text_extra", [])),
|
||||||
|
"user_id": user_info.get("uid"),
|
||||||
|
"sec_uid": user_info.get("sec_uid"),
|
||||||
|
"short_user_id": user_info.get("short_id"),
|
||||||
|
"user_unique_id": user_info.get("unique_id"),
|
||||||
|
"user_signature": user_info.get("signature"),
|
||||||
|
"nickname": user_info.get("nickname"),
|
||||||
|
"avatar": avatar_info.get("url_list", [""])[0],
|
||||||
|
"sub_comment_count": comment_item.get("reply_comment_total", 0),
|
||||||
|
"last_modify_ts": utils.get_current_timestamp(),
|
||||||
|
}
|
||||||
|
# do something ...
|
||||||
|
print(f"update aweme comment: {comment_id}, content: {local_db_item.get('content')}")
|
||||||
|
|
@ -4,3 +4,4 @@ playwright==1.33.0
|
||||||
aioredis==2.0.1
|
aioredis==2.0.1
|
||||||
tenacity==8.2.2
|
tenacity==8.2.2
|
||||||
tornado==6.3.2
|
tornado==6.3.2
|
||||||
|
PyExecJS==1.5.1
|
||||||
Loading…
Reference in New Issue