feat: 小红书增加手机号自动登录模式
This commit is contained in:
parent
c0a783fa35
commit
8206f83639
46
README.md
46
README.md
|
|
@ -3,13 +3,16 @@
|
|||
> 本仓库的所有内容仅供学习和参考之用,禁止用于商业用途。任何人或组织不得将本仓库的内容用于非法用途或侵犯他人合法权益。本仓库所涉及的爬虫技术仅用于学习和研究,不得用于对其他平台进行大规模爬虫或其他非法行为。对于因使用本仓库内容而引起的任何法律责任,本仓库不承担任何责任。使用本仓库的内容即表示您同意本免责声明的所有条款和条件。
|
||||
|
||||
# 仓库描述
|
||||
这个代码仓库是一个利用[playwright](https://playwright.dev/)的爬虫程序
|
||||
可以准确地爬取小红书、抖音的笔记、评论等信息,原理是:利用playwright登录成功后,保留登录成功后的上下文浏览器环境,通过上下文浏览器环境执行JS表达式获取一些加密参数,再使用python的httpx发起异步请求,相当于使用Playwright搭桥,免去了复现核心加密JS代码,逆向难度大大降低。
|
||||
这个代码仓库是一个利用[playwright](https://playwright.dev/)的爬虫程序,可以准确地爬取小红书、抖音的笔记、评论等信息。
|
||||
原理:利用playwright登录成功后,保留登录成功后的上下文浏览器环境,通过上下文浏览器环境执行JS表达式获取一些加密参数,
|
||||
再使用[httpx](https://github.com/encode/httpx)发起异步请求,相当于使用Playwright搭桥,免去了复现核心加密JS代码,逆向难度大大降低。
|
||||
|
||||
|
||||
|
||||
## 主要功能
|
||||
|
||||
- [x] 爬取小红书笔记、评论
|
||||
- [x] 小红书笔记、评论
|
||||
- [x] 二维码扫描登录 | 手机号+验证码自动登录
|
||||
- [ ] To do 抖音滑块
|
||||
- [ ] To do 爬取抖音视频、评论
|
||||
|
||||
## 技术栈
|
||||
|
|
@ -25,13 +28,40 @@
|
|||
2. 安装playwright浏览器驱动
|
||||
`playwright install`
|
||||
3. 运行爬虫程序
|
||||
`python main.py --platform xhs --keywords 健身`
|
||||
`python main.py --platform xhs --keywords 健身 --lt qrcode`
|
||||
4. 打开小红书扫二维码登录
|
||||
|
||||
## 运行截图
|
||||
## 小红书运行截图
|
||||
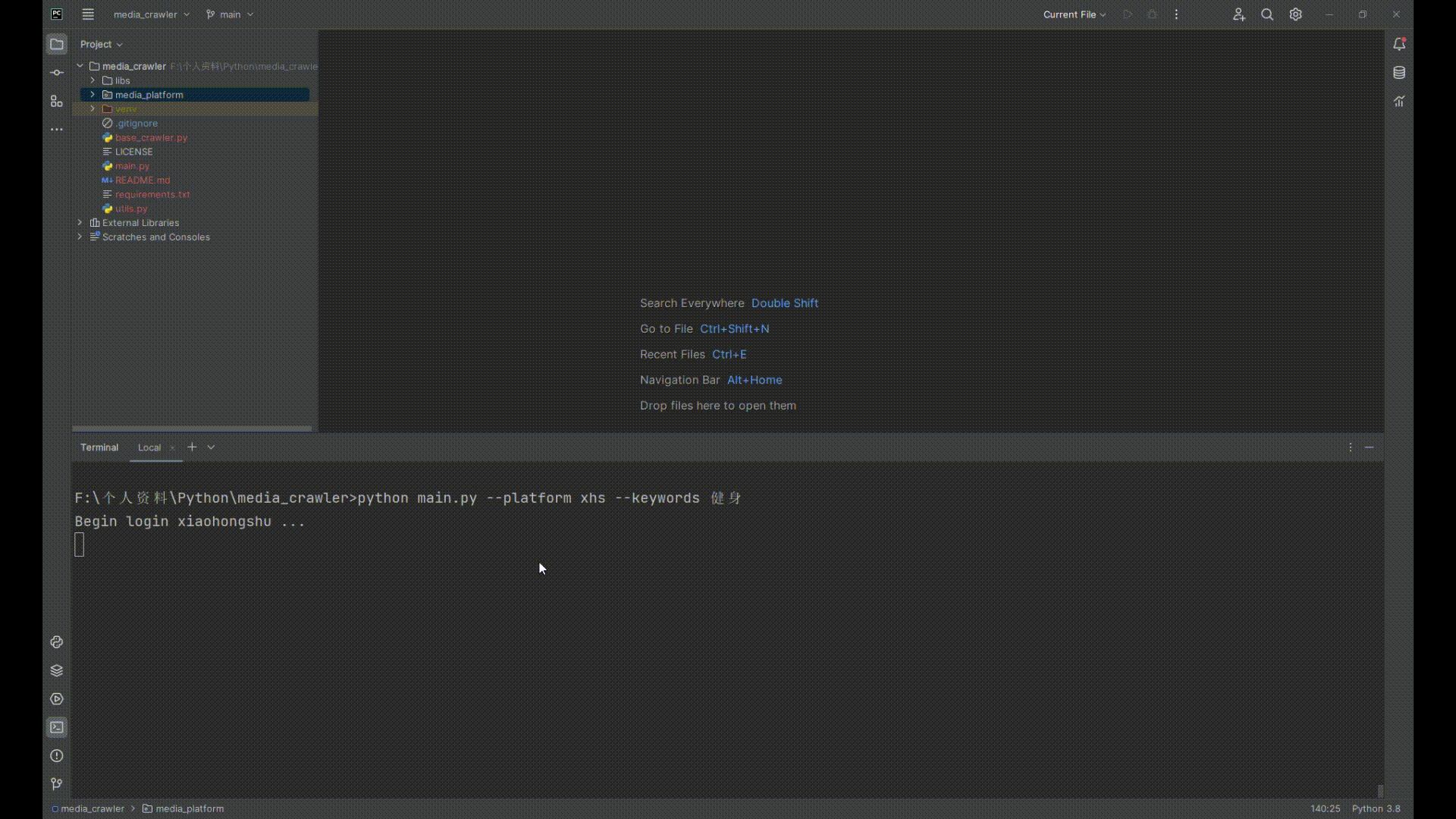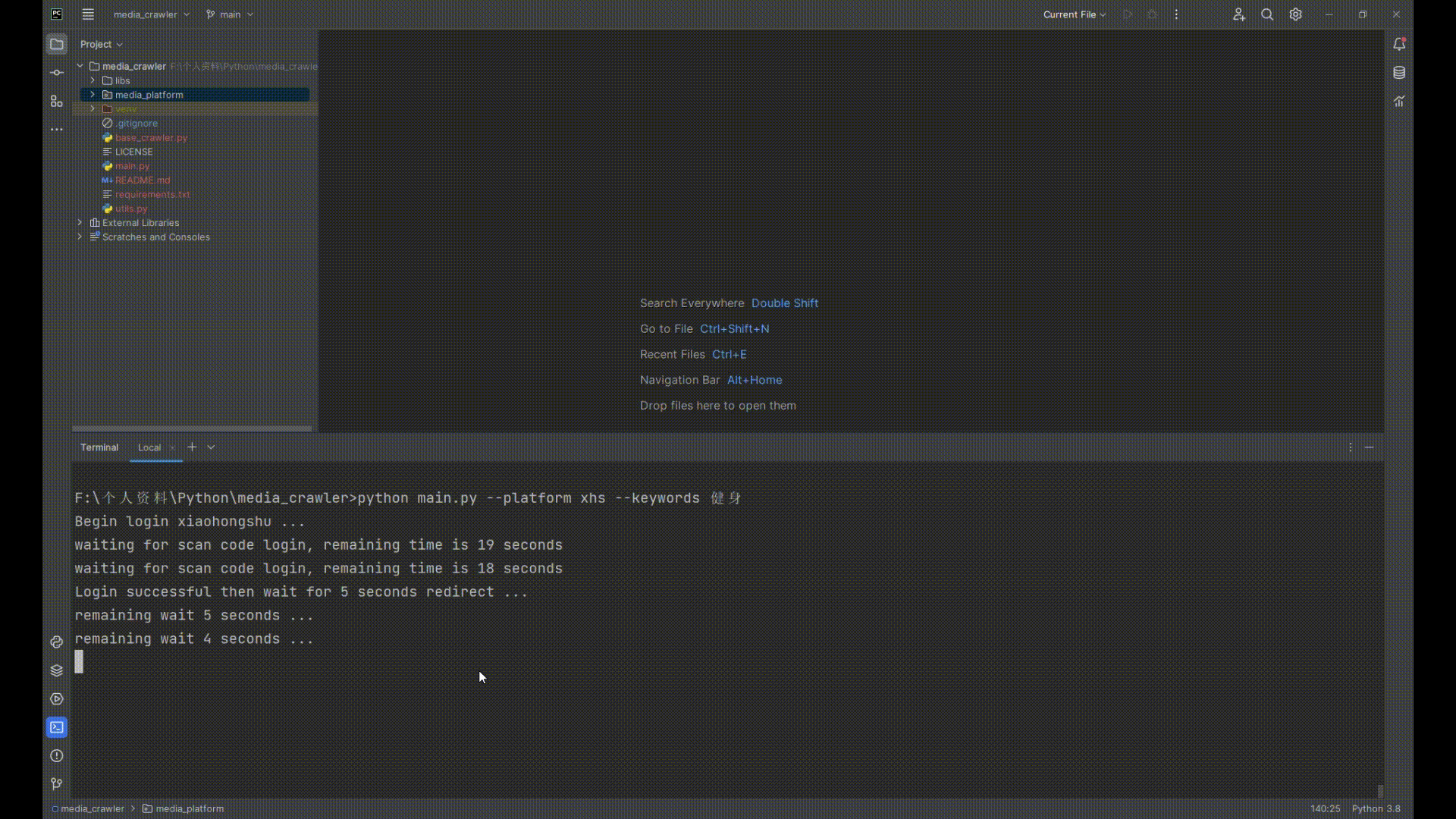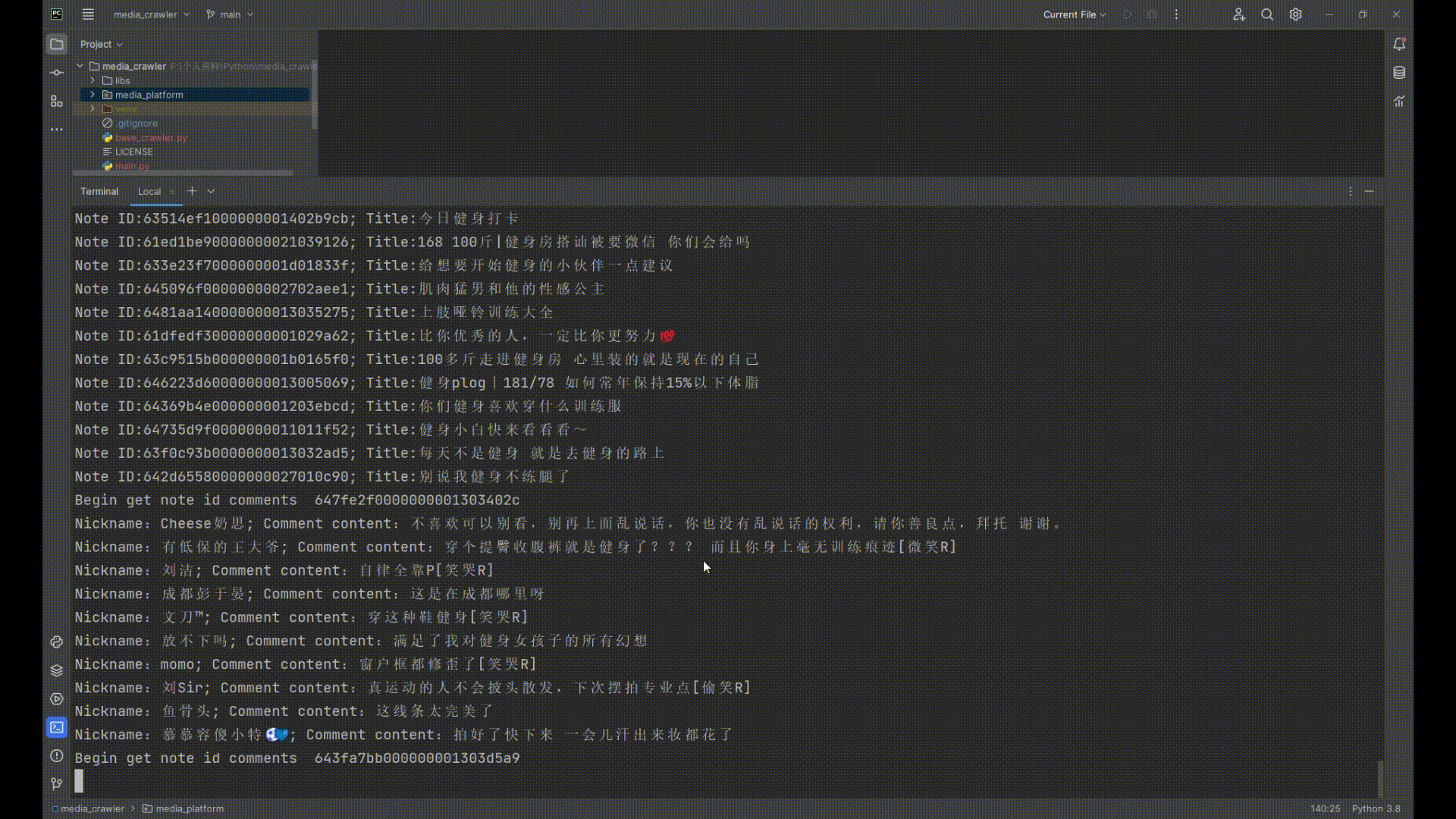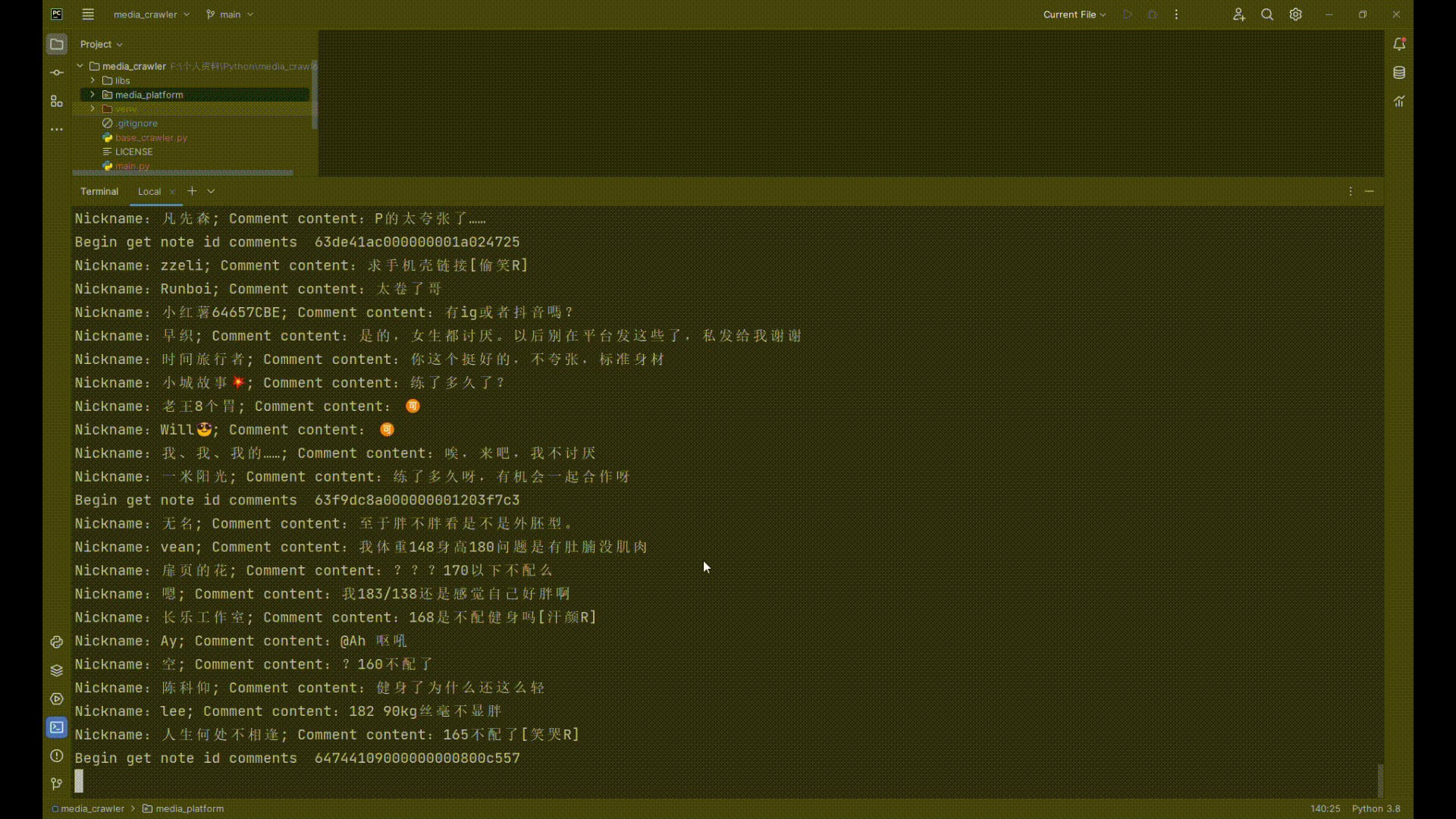
|
||||
|
||||
## 抖音运行截图
|
||||
- [ ] To do
|
||||
|
||||
## 关于手机号+验证码登录的说明
|
||||
当在小红书等平台上使用手机登录时,发送验证码后,使用短信转发器完成验证码转发。
|
||||
|
||||
准备工作:
|
||||
- 安卓机1台(IOS没去研究,理论上监控短信也是可行的)
|
||||
- 安装短信转发软件 [参考仓库](https://github.com/pppscn/SmsForwarder)
|
||||
- 转发软件中配置WEBHOOK相关的信息,主要分为 消息模板(请查看本项目中的recv_sms_notification.py)、一个能push短信通知的API地址
|
||||
- push的API地址一般是需要绑定一个域名的(当然也可以是内网的IP地址),我用的是内网穿透方式,会有一个免费的域名绑定到内网的web server,内网穿透工具 [ngrok](https://ngrok.com/docs/)
|
||||
- 安装redis并设置一个密码 [redis安装](https://www.cnblogs.com/hunanzp/p/12304622.html)
|
||||
- 执行 `python recv_sms_notification.py` 等待短信转发器发送HTTP通知
|
||||
- 执行手机号登录的爬虫程序 `python main.py --platform xhs --keywords 健身 --lt phone --phone 13812345678`
|
||||
|
||||
备注:
|
||||
- 小红书这边一个手机号一天只能发10条短信(悠着点),目前在发验证码时还未触发滑块验证,估计多了之后也会有~
|
||||
- 短信转发软件会不会监控自己手机上其他短信内容?(理论上应该不会,因为[短信转发仓库](https://github.com/pppscn/SmsForwarder)star还是蛮多的)
|
||||
|
||||
## 支持一下
|
||||
- 如果该项目对你有帮助,star一下 ❤️❤️❤️
|
||||
- 如果该项目对你有帮助,可以请作者喝杯咖啡😄😄😄
|
||||
<img src="https://s2.loli.net/2023/06/16/luz5tyeHgFxhbfc.png" style="margin-top:10px">
|
||||
|
||||
|
||||
|
||||
## 参考
|
||||
本仓库中小红书代码部分来自[ReaJason的xhs仓库](https://github.com/ReaJason/xhs),感谢ReaJason
|
||||
|
||||
- xhs客户端 [ReaJason的xhs仓库](https://github.com/ReaJason/xhs)
|
||||
- 短信转发 [参考仓库](https://github.com/pppscn/SmsForwarder)
|
||||
- 内网穿透工具 [ngrok](https://ngrok.com/docs/)
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,10 @@
|
|||
# config file
|
||||
|
||||
platform = "xhs"
|
||||
keyword = "健身"
|
||||
login_type = "qrcode" # qrcode or phone
|
||||
login_phone = "13812345678" # your login phone
|
||||
|
||||
# redis config
|
||||
redis_db_host = "redis://127.0.0.1"
|
||||
redis_db_pwd = "123456" # your redis password
|
||||
10
main.py
10
main.py
|
|
@ -2,6 +2,7 @@ import sys
|
|||
import asyncio
|
||||
import argparse
|
||||
|
||||
import config
|
||||
from media_platform.douyin import DouYinCrawler
|
||||
from media_platform.xhs import XiaoHongShuCrawler
|
||||
|
||||
|
|
@ -20,12 +21,17 @@ class CrawlerFactory:
|
|||
async def main():
|
||||
# define command line params ...
|
||||
parser = argparse.ArgumentParser(description='Media crawler program.')
|
||||
parser.add_argument('--platform', type=str, help='Media platform select (xhs|dy)...', default="xhs")
|
||||
parser.add_argument('--keywords', type=str, help='Search note/page keywords...', default="健身")
|
||||
parser.add_argument('--platform', type=str, help='Media platform select (xhs|dy)...', default=config.platform)
|
||||
parser.add_argument('--keywords', type=str, help='Search note/page keywords...', default=config.keyword)
|
||||
parser.add_argument('--lt', type=str, help='Login type (qrcode | phone)', default=config.login_type)
|
||||
parser.add_argument('--phone', type=str, help='Login phone', default=config.login_phone)
|
||||
|
||||
args = parser.parse_args()
|
||||
crawler = CrawlerFactory().create_crawler(platform=args.platform)
|
||||
crawler.init_config(
|
||||
keywords=args.keywords,
|
||||
login_phone=args.phone,
|
||||
login_type=args.lt
|
||||
)
|
||||
await crawler.start()
|
||||
|
||||
|
|
|
|||
|
|
@ -163,13 +163,15 @@ class XHSClient:
|
|||
}
|
||||
return await self.get(uri, params)
|
||||
|
||||
async def get_note_all_comments(self, note_id: str, crawl_interval: int = 1):
|
||||
"""get note all comments include sub comments
|
||||
|
||||
:param crawl_interval:
|
||||
:param note_id: note id you want to fetch
|
||||
:type note_id: str
|
||||
async def get_note_all_comments(self, note_id: str, crawl_interval: float = 1.0, is_fetch_sub_comments=False):
|
||||
"""
|
||||
get note all comments include sub comments
|
||||
:param note_id:
|
||||
:param crawl_interval:
|
||||
:param is_fetch_sub_comments:
|
||||
:return:
|
||||
"""
|
||||
|
||||
result = []
|
||||
comments_has_more = True
|
||||
comments_cursor = ""
|
||||
|
|
@ -178,6 +180,10 @@ class XHSClient:
|
|||
comments_has_more = comments_res.get("has_more", False)
|
||||
comments_cursor = comments_res.get("cursor", "")
|
||||
comments = comments_res["comments"]
|
||||
if not is_fetch_sub_comments:
|
||||
result.extend(comments)
|
||||
continue
|
||||
# handle get sub comments
|
||||
for comment in comments:
|
||||
result.append(comment)
|
||||
cur_sub_comment_count = int(comment["sub_comment_count"])
|
||||
|
|
|
|||
|
|
@ -1,32 +1,45 @@
|
|||
import sys
|
||||
import random
|
||||
import asyncio
|
||||
from asyncio import Task
|
||||
from typing import Optional, List, Dict
|
||||
|
||||
import aioredis
|
||||
from tenacity import (
|
||||
retry,
|
||||
stop_after_attempt,
|
||||
wait_fixed,
|
||||
retry_if_result
|
||||
)
|
||||
from playwright.async_api import Page
|
||||
from playwright.async_api import Cookie
|
||||
from playwright.async_api import BrowserContext
|
||||
from playwright.async_api import async_playwright
|
||||
|
||||
import utils
|
||||
import config
|
||||
from .client import XHSClient
|
||||
from base_crawler import Crawler
|
||||
from models import xhs as xhs_model
|
||||
|
||||
|
||||
class XiaoHongShuCrawler(Crawler):
|
||||
def __init__(self):
|
||||
self.login_phone = None
|
||||
self.login_type = None
|
||||
self.keywords = None
|
||||
self.scan_qrcode_time = None
|
||||
self.cookies: Optional[List[Cookie]] = None
|
||||
self.browser_context: Optional[BrowserContext] = None
|
||||
self.context_page: Optional[Page] = None
|
||||
self.proxy: Optional[Dict] = None
|
||||
self.user_agent = utils.get_user_agent()
|
||||
self.xhs_client: Optional[XHSClient] = None
|
||||
self.login_url = "https://www.xiaohongshu.com"
|
||||
self.scan_qrcode_time = 20 # second
|
||||
self.index_url = "https://www.xiaohongshu.com"
|
||||
|
||||
def init_config(self, **kwargs):
|
||||
self.keywords = kwargs.get("keywords")
|
||||
self.login_type = kwargs.get("login_type")
|
||||
self.login_phone = kwargs.get("login_phone")
|
||||
|
||||
async def update_cookies(self):
|
||||
self.cookies = await self.browser_context.cookies()
|
||||
|
|
@ -35,7 +48,7 @@ class XiaoHongShuCrawler(Crawler):
|
|||
async with async_playwright() as playwright:
|
||||
# launch browser and create single browser context
|
||||
chromium = playwright.chromium
|
||||
browser = await chromium.launch(headless=True)
|
||||
browser = await chromium.launch(headless=False)
|
||||
self.browser_context = await browser.new_context(
|
||||
viewport={"width": 1920, "height": 1080},
|
||||
user_agent=self.user_agent,
|
||||
|
|
@ -45,7 +58,7 @@ class XiaoHongShuCrawler(Crawler):
|
|||
# execute JS to bypass anti automation/crawler detection
|
||||
await self.browser_context.add_init_script(path="libs/stealth.min.js")
|
||||
self.context_page = await self.browser_context.new_page()
|
||||
await self.context_page.goto(self.login_url)
|
||||
await self.context_page.goto(self.index_url)
|
||||
|
||||
# scan qrcode login
|
||||
await self.login()
|
||||
|
|
@ -67,59 +80,106 @@ class XiaoHongShuCrawler(Crawler):
|
|||
)
|
||||
|
||||
# Search for notes and retrieve their comment information.
|
||||
note_res = await self.search_posts()
|
||||
for post_item in note_res.get("items"):
|
||||
note_id = post_item.get("id")
|
||||
await self.get_comments(note_id=note_id)
|
||||
await asyncio.sleep(1)
|
||||
await self.search_posts()
|
||||
|
||||
# block main crawler coroutine
|
||||
await asyncio.Event().wait()
|
||||
|
||||
async def login(self):
|
||||
"""login xiaohongshu website and keep webdriver login state"""
|
||||
print("Begin login xiaohongshu ...")
|
||||
# There are two ways to log in:
|
||||
# 1. Semi-automatic: Log in by scanning the QR code.
|
||||
# 2. Fully automatic: Log in using forwarded text message notifications
|
||||
# which includes mobile phone number and verification code.
|
||||
if self.login_type == "qrcode":
|
||||
await self.login_by_qrcode()
|
||||
elif self.login_type == "phone":
|
||||
await self.login_by_mobile()
|
||||
else:
|
||||
pass
|
||||
|
||||
async def login_by_mobile(self):
|
||||
print("Start executing mobile phone number + verification code login on Xiaohongshu. ...")
|
||||
login_container_ele = await self.context_page.wait_for_selector("div.login-container")
|
||||
# Fill login phone
|
||||
input_ele = await login_container_ele.query_selector("label.phone > input")
|
||||
await input_ele.fill(self.login_phone)
|
||||
await asyncio.sleep(0.5)
|
||||
|
||||
# Click to send verification code and fill it from redis server.
|
||||
send_btn_ele = await login_container_ele.query_selector("label.auth-code > span")
|
||||
await send_btn_ele.click()
|
||||
sms_code_input_ele = await login_container_ele.query_selector("label.auth-code > input")
|
||||
submit_btn_ele = await login_container_ele.query_selector("div.input-container > button")
|
||||
redis_obj = aioredis.from_url(url=config.redis_db_host, password=config.redis_db_pwd, decode_responses=True)
|
||||
max_get_sms_code_time = 60 * 2
|
||||
current_cookie = await self.browser_context.cookies()
|
||||
_, cookie_dict = utils.convert_cookies(current_cookie)
|
||||
no_logged_in_session = cookie_dict.get("web_session")
|
||||
while max_get_sms_code_time > 0:
|
||||
print(f"get sms code from redis remaining time {max_get_sms_code_time}s ...")
|
||||
await asyncio.sleep(1)
|
||||
sms_code_key = f"xhs_{self.login_phone}"
|
||||
sms_code_value = await redis_obj.get(sms_code_key)
|
||||
if not sms_code_value:
|
||||
max_get_sms_code_time -= 1
|
||||
continue
|
||||
|
||||
await sms_code_input_ele.fill(value=sms_code_value) # Enter SMS verification code.
|
||||
await asyncio.sleep(0.5)
|
||||
agree_privacy_ele = self.context_page.locator("xpath=//div[@class='agreements']//*[local-name()='svg']")
|
||||
await agree_privacy_ele.click() # Click "Agree" to the privacy policy.
|
||||
await asyncio.sleep(0.5)
|
||||
|
||||
await submit_btn_ele.click() # Click login button
|
||||
# todo ... It is necessary to check the correctness of the verification code,
|
||||
# as it is possible that the entered verification code is incorrect.
|
||||
break
|
||||
|
||||
login_flag: bool = await self.check_login_state(no_logged_in_session)
|
||||
if not login_flag:
|
||||
print("login failed please confirm sms code ...")
|
||||
sys.exit()
|
||||
|
||||
wait_redirect_seconds = 5
|
||||
print(f"Login successful then wait for {wait_redirect_seconds} seconds redirect ...")
|
||||
await asyncio.sleep(wait_redirect_seconds)
|
||||
|
||||
async def login_by_qrcode(self):
|
||||
"""login xiaohongshu website and keep webdriver login state"""
|
||||
print("Start scanning QR code to log in to Xiaohongshu. ...")
|
||||
|
||||
# find login qrcode
|
||||
base64_qrcode_img = await utils.find_login_qrcode(
|
||||
self.context_page,
|
||||
selector="div.login-container > div.left > div.qrcode > img"
|
||||
)
|
||||
current_cookie = await self.browser_context.cookies()
|
||||
_, cookie_dict = utils.convert_cookies(current_cookie)
|
||||
no_logged_in_session = cookie_dict.get("web_session")
|
||||
if not base64_qrcode_img:
|
||||
|
||||
if await self.check_login_state(no_logged_in_session):
|
||||
return
|
||||
# todo ...if this website does not automatically popup login dialog box, we will manual click login button
|
||||
print("login failed , have not found qrcode please check ....")
|
||||
sys.exit()
|
||||
|
||||
# get not logged session
|
||||
current_cookie = await self.browser_context.cookies()
|
||||
_, cookie_dict = utils.convert_cookies(current_cookie)
|
||||
no_logged_in_session = cookie_dict.get("web_session")
|
||||
|
||||
# show login qrcode
|
||||
utils.show_qrcode(base64_qrcode_img)
|
||||
|
||||
while self.scan_qrcode_time > 0:
|
||||
await asyncio.sleep(1)
|
||||
self.scan_qrcode_time -= 1
|
||||
print(f"waiting for scan code login, remaining time is {self.scan_qrcode_time} seconds")
|
||||
# get login state from browser
|
||||
if await self.check_login_state(no_logged_in_session):
|
||||
# If the QR code login is successful, you need to wait for a moment.
|
||||
# Because there will be a second redirection after successful login
|
||||
# executing JS during this period may be performed in a Page that has already been destroyed.
|
||||
wait_for_seconds = 5
|
||||
print(f"Login successful then wait for {wait_for_seconds} seconds redirect ...")
|
||||
while wait_for_seconds > 0:
|
||||
await asyncio.sleep(1)
|
||||
print(f"remaining wait {wait_for_seconds} seconds ...")
|
||||
wait_for_seconds -= 1
|
||||
break
|
||||
else:
|
||||
print(f"waiting for scan code login, remaining time is 20s")
|
||||
login_flag: bool = await self.check_login_state(no_logged_in_session)
|
||||
if not login_flag:
|
||||
print("login failed please confirm ...")
|
||||
sys.exit()
|
||||
|
||||
wait_redirect_seconds = 5
|
||||
print(f"Login successful then wait for {wait_redirect_seconds} seconds redirect ...")
|
||||
await asyncio.sleep(wait_redirect_seconds)
|
||||
|
||||
@retry(stop=stop_after_attempt(30), wait=wait_fixed(1), retry=retry_if_result(lambda value: value is False))
|
||||
async def check_login_state(self, no_logged_in_session: str) -> bool:
|
||||
"""Check if the current login status is successful and return True otherwise return False"""
|
||||
# If login is unsuccessful, a retry exception will be thrown.
|
||||
current_cookie = await self.browser_context.cookies()
|
||||
_, cookie_dict = utils.convert_cookies(current_cookie)
|
||||
current_web_session = cookie_dict.get("web_session")
|
||||
|
|
@ -128,26 +188,37 @@ class XiaoHongShuCrawler(Crawler):
|
|||
return False
|
||||
|
||||
async def search_posts(self):
|
||||
# This function only retrieves the first 10 note
|
||||
# And you can continue to make requests to obtain more by checking the boolean status of "has_more".
|
||||
print("Begin search xiaohongshu keywords: ", self.keywords)
|
||||
posts_res = await self.xhs_client.get_note_by_keyword(keyword=self.keywords)
|
||||
print("Begin search xiaohongshu keywords")
|
||||
# It is possible to modify the source code to allow for the passing of a batch of keywords.
|
||||
for keyword in [self.keywords]:
|
||||
note_list: List[str] = []
|
||||
max_note_len = 10
|
||||
page = 1
|
||||
while max_note_len > 0:
|
||||
posts_res = await self.xhs_client.get_note_by_keyword(
|
||||
keyword=keyword,
|
||||
page=page,
|
||||
)
|
||||
page += 1
|
||||
for post_item in posts_res.get("items"):
|
||||
max_note_len -= 1
|
||||
note_id = post_item.get("id")
|
||||
title = post_item.get("note_card", {}).get("display_title")
|
||||
print(f"Note ID:{note_id}; Title:{title}")
|
||||
# todo record note or save to db or csv
|
||||
return posts_res
|
||||
note_detail = await self.xhs_client.get_note_by_id(note_id)
|
||||
await xhs_model.update_xhs_note(note_detail)
|
||||
await asyncio.sleep(0.05)
|
||||
note_list.append(note_id)
|
||||
print(f"keyword:{keyword}, note_list:{note_list}")
|
||||
await self.batch_get_note_comments(note_list)
|
||||
|
||||
async def batch_get_note_comments(self, note_list: List[str]):
|
||||
task_list: List[Task] = []
|
||||
for note_id in note_list:
|
||||
task = asyncio.create_task(self.get_comments(note_id), name=note_id)
|
||||
task_list.append(task)
|
||||
await asyncio.wait(task_list)
|
||||
|
||||
async def get_comments(self, note_id: str):
|
||||
# This function only retrieves the first 10 comments
|
||||
# And you can continue to make requests to obtain more by checking the boolean status of "has_more".
|
||||
print("Begin get note id comments ", note_id)
|
||||
res = await self.xhs_client.get_note_comments(note_id=note_id)
|
||||
# res = await self.xhs_client.get_note_all_comments(note_id=note_id)
|
||||
for comment in res.get("comments"):
|
||||
nick_name = comment.get("user_info").get("nickname")
|
||||
comment_content = comment.get("content")
|
||||
print(f"Nickname:{nick_name}; Comment content:{comment_content}")
|
||||
# todo save to db or csv
|
||||
return res
|
||||
all_comments = await self.xhs_client.get_note_all_comments(note_id=note_id, crawl_interval=random.random())
|
||||
for comment in all_comments:
|
||||
await xhs_model.update_xhs_note_comment(note_id=note_id, comment_item=comment)
|
||||
|
|
|
|||
|
|
@ -0,0 +1 @@
|
|||
from .m_xhs import *
|
||||
|
|
@ -0,0 +1,46 @@
|
|||
from typing import Dict
|
||||
|
||||
import utils
|
||||
|
||||
|
||||
async def update_xhs_note(note_item: Dict):
|
||||
note_id = note_item.get("note_id")
|
||||
user_info = note_item.get("user", {})
|
||||
interact_info = note_item.get("interact_info")
|
||||
image_list = note_item.get("image_list")
|
||||
|
||||
local_db_item = {
|
||||
"note_id": note_item.get("note_id"),
|
||||
"type": note_item.get("type"),
|
||||
"title": note_item.get("title"),
|
||||
"desc": note_item.get("desc", ""),
|
||||
"time": note_item.get("time"),
|
||||
"last_update_time": note_item.get("last_update_time", 0),
|
||||
"user_id": user_info.get("user_id"),
|
||||
"nickname": user_info.get("nickname"),
|
||||
"avatar": user_info.get("avatar"),
|
||||
"ip_location": note_item.get("ip_location", ""),
|
||||
"image_list": ','.join([img.get('url') for img in image_list]),
|
||||
"last_modify_ts": utils.get_current_timestamp(),
|
||||
}
|
||||
# do something ...
|
||||
print("update note:", local_db_item)
|
||||
|
||||
|
||||
async def update_xhs_note_comment(note_id: str, comment_item: Dict):
|
||||
user_info = comment_item.get("user_info")
|
||||
comment_id = comment_item.get("id")
|
||||
local_db_item = {
|
||||
"comment_id": comment_id,
|
||||
"create_time": comment_item.get("create_time"),
|
||||
"ip_location": comment_item.get("ip_location"),
|
||||
"note_id": note_id,
|
||||
"content": comment_item.get("content"),
|
||||
"user_id": user_info.get("user_id"),
|
||||
"nickname": user_info.get("nickname"),
|
||||
"avatar": user_info.get("image"),
|
||||
"sub_comment_count": comment_item.get("sub_comment_count"),
|
||||
"last_modify_ts": utils.get_current_timestamp(),
|
||||
}
|
||||
# do something ...
|
||||
print("update comment:", local_db_item)
|
||||
|
|
@ -0,0 +1,85 @@
|
|||
# Start an HTTP server to receive SMS forwarding notifications and store them in Redis.
|
||||
import re
|
||||
import json
|
||||
import asyncio
|
||||
|
||||
import aioredis
|
||||
import tornado.web
|
||||
|
||||
import config
|
||||
|
||||
|
||||
def extract_verification_code(message) -> str:
|
||||
"""
|
||||
Extract verification code of 6 digits from the SMS.
|
||||
"""
|
||||
pattern = re.compile(r'\b[0-9]{6}\b')
|
||||
codes = pattern.findall(message)
|
||||
return codes[0] if codes and len(codes) > 0 else ""
|
||||
|
||||
|
||||
class RecvSmsNotificationHandler(tornado.web.RequestHandler):
|
||||
async def get(self):
|
||||
self.set_status(404)
|
||||
self.write("404")
|
||||
|
||||
async def post(self):
|
||||
# GitHub address for the SMS forwarding function:https://github.com/pppscn/SmsForwarder
|
||||
# Document address::https://gitee.com/pp/SmsForwarder/wikis/pages?sort_id=6040999&doc_id=1821427
|
||||
# Forwarding channel definition:
|
||||
# {
|
||||
# "platform": "xhs",
|
||||
# "current_number": "138xxxxxxxx",
|
||||
# "from_number": "[from]",
|
||||
# "sms_content": "[org_content]",
|
||||
# "timestamp": "[timestamp]"
|
||||
# }
|
||||
|
||||
# SMS message body:
|
||||
# {
|
||||
# 'platform': 'xhs', # or dy
|
||||
# 'current_number': '138xxxxxxxx',
|
||||
# 'from_number': '1069421xxx134',
|
||||
# 'sms_content': '【小红书】您的验证码是: 171959, 3分钟内有效。请勿向他人泄漏。如非本人操作,可忽略本消息。',
|
||||
# 'timestamp': '1686720601614'
|
||||
# }
|
||||
request_body = self.request.body.decode("utf-8")
|
||||
req_body_dict = json.loads(request_body)
|
||||
print("recv sms notification and body content: ", req_body_dict)
|
||||
redis_obj = aioredis.from_url(url=config.redis_db_host, password=config.redis_db_pwd, decode_responses=True)
|
||||
sms_content = req_body_dict.get("sms_content")
|
||||
sms_code = extract_verification_code(sms_content)
|
||||
if sms_code:
|
||||
# Save the verification code in Redis and set the expiration time to 3 minutes.
|
||||
# Use Redis string data structure, in the following format:
|
||||
# xhs_138xxxxxxxx -> 171959
|
||||
key = f"{req_body_dict.get('platform')}_{req_body_dict.get('current_number')}"
|
||||
await redis_obj.set(name=key, value=sms_code, ex=60 * 3)
|
||||
self.set_status(200)
|
||||
self.write("ok")
|
||||
|
||||
|
||||
class Application(tornado.web.Application):
|
||||
def __init__(self):
|
||||
handlers = [(r'/', RecvSmsNotificationHandler)]
|
||||
settings = dict(
|
||||
gzip=True,
|
||||
autoescape=None,
|
||||
autoreload=True
|
||||
)
|
||||
super(Application, self).__init__(handlers, **settings)
|
||||
|
||||
|
||||
async def main():
|
||||
app = Application()
|
||||
app.listen(port=9435)
|
||||
print("Recv sms notification app running ...")
|
||||
shutdown_event = tornado.locks.Event()
|
||||
await shutdown_event.wait()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
try:
|
||||
asyncio.run(main())
|
||||
except KeyboardInterrupt:
|
||||
pass
|
||||
|
|
@ -1,3 +1,6 @@
|
|||
httpx==0.24.0
|
||||
Pillow==9.5.0
|
||||
playwright==1.33.0
|
||||
aioredis==2.0.1
|
||||
tenacity==8.2.2
|
||||
tornado==6.3.2
|
||||
18
utils.py
18
utils.py
|
|
@ -1,3 +1,5 @@
|
|||
import re
|
||||
import time
|
||||
import random
|
||||
import base64
|
||||
from io import BytesIO
|
||||
|
|
@ -57,3 +59,19 @@ def convert_cookies(cookies: Optional[List[Cookie]]) -> Tuple[str, Dict]:
|
|||
for cookie in cookies:
|
||||
cookie_dict[cookie.get('name')] = cookie.get('value')
|
||||
return cookies_str, cookie_dict
|
||||
|
||||
|
||||
def get_current_timestamp():
|
||||
return int(time.time() * 1000)
|
||||
|
||||
|
||||
def match_interact_info_count(count_str: str) -> int:
|
||||
if not count_str:
|
||||
return 0
|
||||
|
||||
match = re.search(r'\d+', count_str)
|
||||
if match:
|
||||
number = match.group()
|
||||
return int(number)
|
||||
else:
|
||||
return 0
|
||||
|
|
|
|||
Loading…
Reference in New Issue