* Add clipspace feature. * feat: copy content to clipspace * feat: paste content from clipspace Extend validation to allow for validating annotated_path in addition to other parameters. Add support for annotated_filepath in folder_paths function. Generalize the '/upload/image' API to allow for uploading images to the 'input', 'temp', or 'output' directories. * rename contentClipboard -> clipspace * Do deep copy for imgs on copy to clipspace. * mask painting on clipspace * add original_imgs into clipspace * Preserve the original image when 'imgs' are modified * robust patch & refactoring folder_paths about annotated_filepath * wip * Only show the Paste menu if the ComfyApp.clipspace is not empty * clipspace feature added maskeditor feature added * instant refresh on paste force triggering 'changed' on paste action * enhance mask painting smooth drawing add brush_size +/- button * robust patch use mouseup event * robust patch again... * subfolder fix on paste logic attach subfolder if subfolder isn't empty * event listener patch add ], [ key event for brush size remove listener on close * Fix button positioning issue related to window height. Change brush size from button to slider. * clean commit * clean code * various bug fixes * paste action - prevent opening upload popup - ensure rendering after widget_value update * view api update - support annotated_filepath * maskeditor layout - prevent covering button by hidden div * remove dbg message * Add cursor functionality to display brush size * refactor: Replace brush preview feature with missionfloyd implementation * missionfloyd implementation * hiding brush preview off the canvas * change brush size on wheel event * keyup -> keydown event * Update web/extensions/core/maskeditor.js Co-authored-by: missionfloyd <missionfloyd@users.noreply.github.com> * Add support for channel-specific image data retrieval in /view API to fix alpha mask loading issue When loading an image with an alpha mask in JavaScript canvas, there is an issue where the alpha and RGB channels are premultiplied. To avoid reliance on JavaScript canvas, I added support for channel-specific image data retrieval in the "/view" API. This allows us to retrieve data for each channel separately and fix the alpha mask loading issue. The changes have been committed to the repository. * Enable brush preview for key and slider events * optimize * preview fix * robust patch * fix copy (clipspace) action imgs[0] copy -> whole imgs copy * support batch images on clipspace, maskeditor * copy/paste bug fixes for batch images enhance selector preview on clipspace menu add img_paste_mode option into clipspace menu * crash fix * print message if clipspace content cannot editable * Update web/extensions/core/maskeditor.js Co-authored-by: missionfloyd <missionfloyd@users.noreply.github.com> * make default img_paste_mode to 'selected' refactor space -> tab * save clipspace files to input/clipspace instead of temp * show "clipspace/filename.png" instead of 'filename.png [clipspace]' in LoadImage/LoadImageMask * refresh fix related to FILE_COMBO * Update web/extensions/core/maskeditor.js Co-authored-by: missionfloyd <missionfloyd@users.noreply.github.com> * Update web/extensions/core/maskeditor.js Co-authored-by: missionfloyd <missionfloyd@users.noreply.github.com> * adjust margin based on missionfloyd impelements * mouse event -> pointer event * pen, touch, mouse drawing patched and tested * Update web/extensions/core/maskeditor.js Co-authored-by: missionfloyd <missionfloyd@users.noreply.github.com> * add comment about touch event. --------- Co-authored-by: Lt.Dr.Data <lt.dr.data@gmail.com> Co-authored-by: missionfloyd <missionfloyd@users.noreply.github.com> |
||
|---|---|---|
| .ci | ||
| .github/workflows | ||
| comfy | ||
| comfy_extras | ||
| custom_nodes | ||
| input | ||
| models | ||
| notebooks | ||
| output | ||
| script_examples | ||
| web | ||
| .gitignore | ||
| LICENSE | ||
| README.md | ||
| comfyui_screenshot.png | ||
| execution.py | ||
| extra_model_paths.yaml.example | ||
| folder_paths.py | ||
| main.py | ||
| nodes.py | ||
| requirements.txt | ||
| server.py | ||
{kind=link}
README.md
ComfyUI
A powerful and modular stable diffusion GUI and backend.
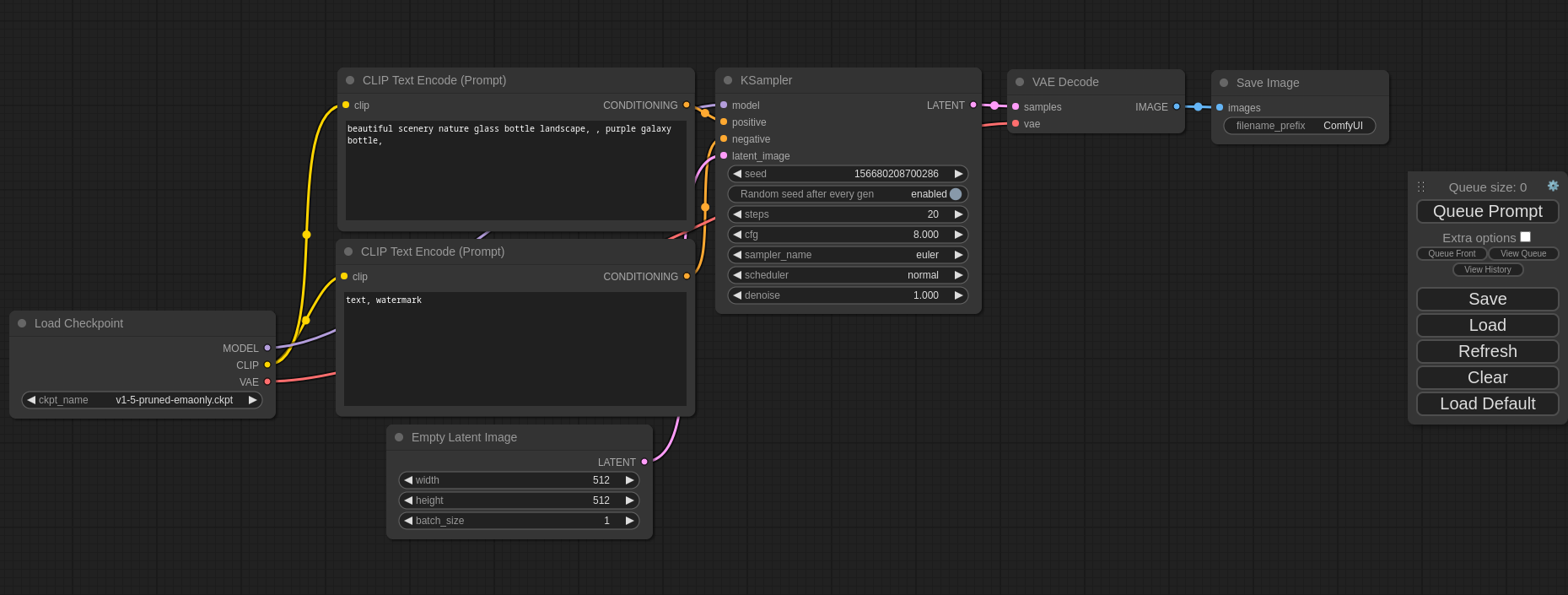
This ui will let you design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. For some workflow examples and see what ComfyUI can do you can check out:
ComfyUI Examples
Installing ComfyUI
Features
- Nodes/graph/flowchart interface to experiment and create complex Stable Diffusion workflows without needing to code anything.
- Fully supports SD1.x and SD2.x
- Asynchronous Queue system
- Many optimizations: Only re-executes the parts of the workflow that changes between executions.
- Command line option:
--lowvramto make it work on GPUs with less than 3GB vram (enabled automatically on GPUs with low vram) - Works even if you don't have a GPU with:
--cpu(slow) - Can load ckpt, safetensors and diffusers models/checkpoints. Standalone VAEs and CLIP models.
- Embeddings/Textual inversion
- Loras (regular, locon and loha)
- Hypernetworks
- Loading full workflows (with seeds) from generated PNG files.
- Saving/Loading workflows as Json files.
- Nodes interface can be used to create complex workflows like one for Hires fix or much more advanced ones.
- Area Composition
- Inpainting with both regular and inpainting models.
- ControlNet and T2I-Adapter
- Upscale Models (ESRGAN, ESRGAN variants, SwinIR, Swin2SR, etc...)
- unCLIP Models
- GLIGEN
- Starts up very fast.
- Works fully offline: will never download anything.
- Config file to set the search paths for models.
Workflow examples can be found on the Examples page
Shortcuts
| Keybind | Explanation |
|---|---|
| Ctrl + Enter | Queue up current graph for generation |
| Ctrl + Shift + Enter | Queue up current graph as first for generation |
| Ctrl + S | Save workflow |
| Ctrl + O | Load workflow |
| Ctrl + A | Select all nodes |
| Ctrl + M | Mute/unmute selected nodes |
| Delete/Backspace | Delete selected nodes |
| Ctrl + Delete/Backspace | Delete the current graph |
| Space | Move the canvas around when held and moving the cursor |
| Ctrl/Shift + Click | Add clicked node to selection |
| Ctrl + C/Ctrl + V | Copy and paste selected nodes (without maintaining connections to outputs of unselected nodes) |
| Ctrl + C/Ctrl + Shift + V | Copy and paste selected nodes (maintaining connections from outputs of unselected nodes to inputs of pasted nodes) |
| Shift + Drag | Move multiple selected nodes at the same time |
| Ctrl + D | Load default graph |
| Q | Toggle visibility of the queue |
| H | Toggle visibility of history |
| R | Refresh graph |
| Double-Click LMB | Open node quick search palette |
Ctrl can also be replaced with Cmd instead for MacOS users
Installing
Windows
There is a portable standalone build for Windows that should work for running on Nvidia GPUs or for running on your CPU only on the releases page.
Direct link to download
Just download, extract and run. Make sure you put your Stable Diffusion checkpoints/models (the huge ckpt/safetensors files) in: ComfyUI\models\checkpoints
How do I share models between another UI and ComfyUI?
See the Config file to set the search paths for models. In the standalone windows build you can find this file in the ComfyUI directory. Rename this file to extra_model_paths.yaml and edit it with your favorite text editor.
Colab Notebook
To run it on colab or paperspace you can use my Colab Notebook here: Link to open with google colab
Manual Install (Windows, Linux)
Git clone this repo.
Put your SD checkpoints (the huge ckpt/safetensors files) in: models/checkpoints
Put your VAE in: models/vae
At the time of writing this pytorch has issues with python versions higher than 3.10 so make sure your python/pip versions are 3.10.
AMD GPUs (Linux only)
AMD users can install rocm and pytorch with pip if you don't have it already installed, this is the command to install the stable version:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/rocm5.4.2
NVIDIA
Nvidia users should install torch and xformers using this command:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118 xformers
Troubleshooting
If you get the "Torch not compiled with CUDA enabled" error, uninstall torch with:
pip uninstall torch
And install it again with the command above.
Dependencies
Install the dependencies by opening your terminal inside the ComfyUI folder and:
pip install -r requirements.txt
After this you should have everything installed and can proceed to running ComfyUI.
Others:
Mac/MPS: There is basic support in the code but until someone makes some install instruction you are on your own.
I already have another UI for Stable Diffusion installed do I really have to install all of these dependencies?
You don't. If you have another UI installed and working with it's own python venv you can use that venv to run ComfyUI. You can open up your favorite terminal and activate it:
source path_to_other_sd_gui/venv/bin/activate
or on Windows:
With Powershell: "path_to_other_sd_gui\venv\Scripts\Activate.ps1"
With cmd.exe: "path_to_other_sd_gui\venv\Scripts\activate.bat"
And then you can use that terminal to run Comfyui without installing any dependencies. Note that the venv folder might be called something else depending on the SD UI.
Running
python main.py
For AMD 6700, 6600 and maybe others
Try running it with this command if you have issues:
HSA_OVERRIDE_GFX_VERSION=10.3.0 python main.py
Notes
Only parts of the graph that have an output with all the correct inputs will be executed.
Only parts of the graph that change from each execution to the next will be executed, if you submit the same graph twice only the first will be executed. If you change the last part of the graph only the part you changed and the part that depends on it will be executed.
Dragging a generated png on the webpage or loading one will give you the full workflow including seeds that were used to create it.
You can use () to change emphasis of a word or phrase like: (good code:1.2) or (bad code:0.8). The default emphasis for () is 1.1. To use () characters in your actual prompt escape them like \( or \).
You can use {day|night}, for wildcard/dynamic prompts. With this syntax "{wild|card|test}" will be randomly replaced by either "wild", "card" or "test" by the frontend every time you queue the prompt. To use {} characters in your actual prompt escape them like: \{ or \}.
To use a textual inversion concepts/embeddings in a text prompt put them in the models/embeddings directory and use them in the CLIPTextEncode node like this (you can omit the .pt extension):
embedding:embedding_filename.pt
Fedora
To get python 3.10 on fedora:
dnf install python3.10
Then you can:
python3.10 -m ensurepip
This will let you use: pip3.10 to install all the dependencies.
How to increase generation speed?
Make sure you use the regular loaders/Load Checkpoint node to load checkpoints. It will auto pick the right settings depending on your GPU.
You can set this command line setting to disable the upcasting to fp32 in some cross attention operations which will increase your speed. Note that this will very likely give you black images on SD2.x models. If you use xformers this option does not do anything.
--dont-upcast-attention
Support and dev channel
Matrix space: #comfyui_space:matrix.org (it's like discord but open source).
QA
Why did you make this?
I wanted to learn how Stable Diffusion worked in detail. I also wanted something clean and powerful that would let me experiment with SD without restrictions.
Who is this for?
This is for anyone that wants to make complex workflows with SD or that wants to learn more how SD works. The interface follows closely how SD works and the code should be much more simple to understand than other SD UIs.